Improving research efficiency, and exploitation
Scraperwiki is a partner on two major EU research projects, NewsReader and TIMON. We specialise in the exploitation and dissemination of results (particularly through the use of Hack Days), bringing professional software engineering standards to projects, and data ingestion and cleaning.
We have a well-established track record of academic collaboration, and staff with academic backgrounds which makes us a highly competent partner.
If you are considering writing a grant application, or have research you wish to turn into a web application, then please get in touch to see how we might be able to help you with your project.
ScraperWiki helps academics:
- Exploit academic research projects in commercial markets
- Build operational systems from research
- Improving software engineering
Contact sales
Case Study: Natural Language Processing research
NewsReader has developed natural language processing technology to make sense of large streams of news data; to convert a myriad of mentions of events across many news articles into a network of actual events, thus making the news analysable. In NewsReader the underlying events and actors are called “instances”, whilst the mentions of those events in news articles are called… “mentions”. Many mentions can refer to one instance. This is key to the new technology that NewsReader is developing: condensing down millions of news articles into a network representing the original events.
ScraperWiki’s role in the project is to provide a mechanism for users of the system to acquire news to process with the technology, to help with the system architecture, open sourcing of the software developed and to foster the exploitation of the work beyond the project. As part of this we have run numerous events and hack days. The purpose is to invite people into the community and to allow them to test drive innovative technology.
We built an “Extract News” tool. We wanted to provide a means for users to feed articles of interest into the NewsReader system. Extract News is a web crawler which scans a website and converts any news-like content into News Annotation Format (NAF) files which are then processed using the NewsReader natural language processing pipeline. NAF is an XML format which the modules of the pipeline use to both receive input and modify as output. We are running our own instance of the processing virtual machine on Amazon AWS. NAF files contain the content and metadata of individual news articles. Once they have passed through the natural language processing pipeline they are collectively processed to extract semantic information which is then fed into a specialised semantic KnowledgeStore, developed at FBK.
ScraperWiki is a UK start-up company that has guts. It develops innovative solutions to make information streams transparent and open using cutting-edge text mining technologies. Especially their effort to make government processes and information public and open is a noble contribution to democracy. They have close ties with a large open source developers community that are eager to build new solutions. I collaborate with ScraperWiki since 2012 in the European NewsReader project and I got to know them as a group of people that can bridge the gap between academia and application developers discovering new types of businesses.
![]() Piek Vossen
Piek Vossen
Professor of Computational Lexicology, Faculty of Arts, VU University, Amsterdam

NewsReader FP7 Project Team Photo in Liverpool
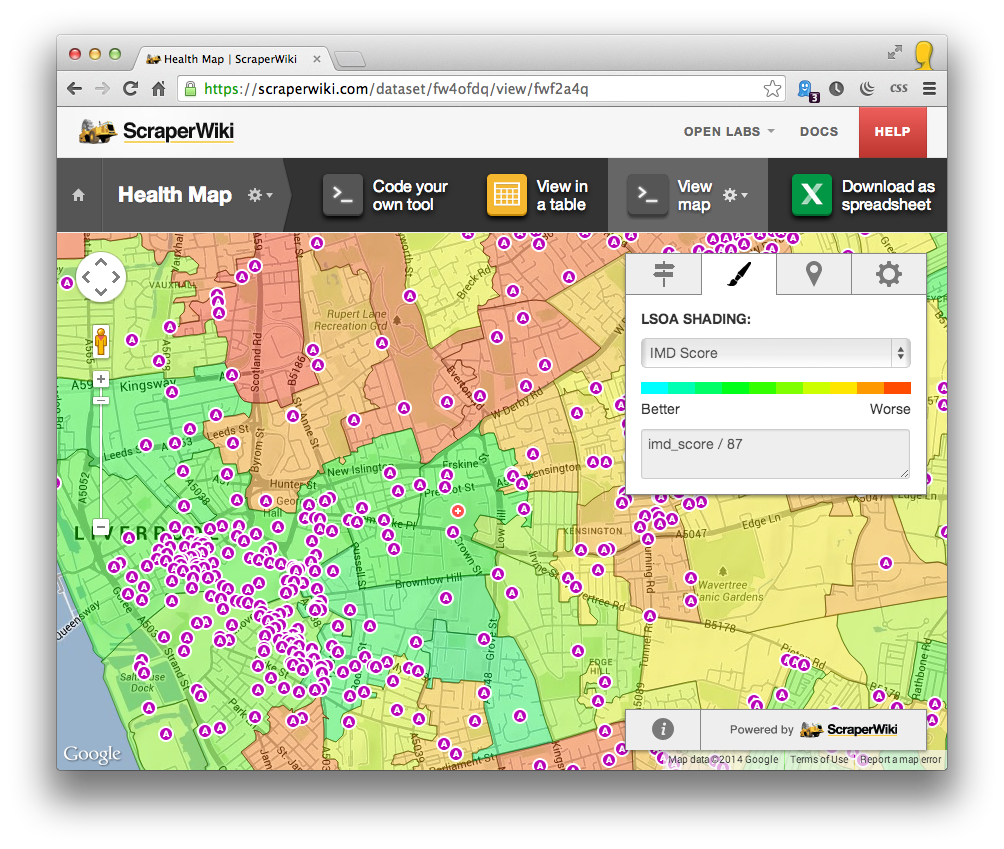
Case Study: Mapping health data for Liverpool researchers
Researchers at Liverpool John Moores University were keen to analyse local hospital, council and demographic data, to spot patterns in ambulance callouts across Merseyside.
ScraperWiki combined business data provided by the local councils, ambulance data from the NWAS, and school location data scraped from the Department for Education website, with data from the national Indices of Deprivation. Each data point was cleaned and geocoded, and presented in an interactive online map for the LJMU researchers to investigate.