From CMS to DMS: C is for Content, D is for Data
This is a joint blog post by Francis Irving, CEO of ScraperWiki, and Rufus Pollock, Founder of the Open Knowledge Foundation. It’s being cross-posted to both blogs.
Content Management Systems, remember those?

It’s 1994. You haven’t heard of the World Wide Web yet.
Your brother goes to a top university. He once overheard some geeks in the computer room making a ‘web site’ consisting of a photo tour of their shared house. He thought it was stupid, Usenet is so much better.
The question – in 1994 did you understand what a Content Management System (CMS) was?
In the intervening years, CMS’s have gone through ups and downs.
Building massive businesses, crashing in the .com collapse. Then a glut, web design agencies all building their own CMS in the early noughties. Ending up with the situation now.
A mature market, commoditised by open source WordPress. Anyone can get a page on the web using Facebook. There’s still room for expensive, proprietary players, newspapers custom make their own, and businesses have fancy intranets.
Data Management Systems, time to meet them!

DMSs are also called "data hubs". Hopefully less patented than this wheel!
It’s 2012. You’ve just about heard of Open Data.
Your nephew researches the Internet at a top university. He says there’s no future in Open Data, no communities have formed round it. Companies aren’t publishing much data yet, and Governments the wrong data reluctantly.
The question – what is a Data Management System (DMS)?
There isn’t a very good one yet. We’re at round about where CMS’s were in the mid 1990s. Most people get by fine without them.
Just as then we wrote HTML in text files by hand and uploaded it by FTP, now we analyse data on our laptops using Excel, and share it with friends by emailing CSV files.
But it reaches the point where using the filesystem and Outlook as your DMS stretches to breaking point. You’ll need a proper one.
Nobody really knows what a proper one will look like yet. We’re all working on it. But we do know what it will enable.
What must a DMS do?
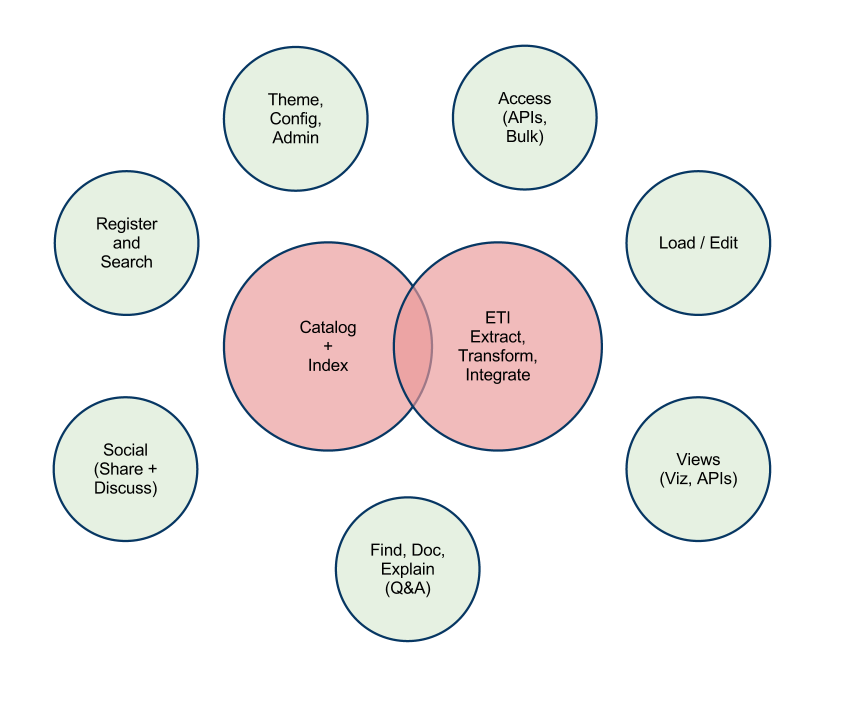
All the things people expect a DMS to do!
A mature DMS will let people do all the following things. Whether as a proprietary monolith, or by slick integration across the web:
- Load and update data from any source (ETL)
- Store datasets and index them for querying
- View, analyse and update data in a tabular interface (spreadsheet)
- Visualise data, for example with charts or maps
- Analyse data, for example with statistics and machine learning
- Organise many people to enter or correct data (crowd-sourcing)
- Measure and ensure the quality of data, and its provenance
- Permissions; data can be open, private or shared
- Find datasets, and organise them to help others find them
- Sell data, sharing processing costs between users
If it sounds like a fat list for a product, that’s because it is. But sometimes the need, the market, pulls you – something simple just won’t do. It has to do or enable, best it can, everything above. (Compare it to the same list for CMSs)
In short, it’s what the elite data wrangling teams inside places like Wolfram Alpha and Google’s Metaweb teams do. But made easier and more visible using standardised tools and protocols.
Who’s making a DMS?
More people than I realise. From the largest IT company to the tiniest startup. Here are some I know about, mention more in the comments:
- Windows / OSX – the desktop serves as a (good enough so far) DMS
- Infochimps/DataMarket – approaching it as a data marketplace
- BuzzData – specialising in the social aspects
- Tableau Public – specialising in visualisation
- Google Spreadsheets – coming from the web spreadsheet direction
- Microsoft Data Hub – corporate information management
- CKAN – started as a data catalogue, growing into more, made by OKFN
- ScraperWiki– coming from the viewpoint of a programmer, good at ETL
- PANDA – making a DMS for newsrooms
They’re all DMS’s because they all naturally grow bad versions of each other’s features. Two examples.
ScraperWiki is particularly good at complex ETL (loading data into a system), yet every DMS has to have a data ingestion interface of at least choosing CSV columns.
CKAN has particularly good metadata, usage and provenance, yet every DMS has to have a way for people to find the data stored in it.
So will they be giant monolithic bits of software?

We standardised the shipping container, can we standardise data interoperation?
We hope not! That didn’t turn out great for CMSs, although there are some businesses providing that.
CMS’s only really came of age when in the mid-noughties everyone realised that WordPress (open source blogging software!) was a better CMS than most CMS’s.
It’s in everyone’s interest that users aren’t locked into one DMS. One of them might have a whizzy content analysis tool that somebody who has data in another DMS wants to use. They should be able to, and easily.
OKFN is about to launch a standards initiative to bring together such things. It’s called Data Protocols.
So far the clearest needs are twofold and mirror each other – pulling and pushing data:
a) a data query protocol/format to allow realtime querying, for example for exploring data. Imagine a Google Refine instance live querying a large dataset on OKFN’s the Data Hub.
b) a data sync protocol/format that is liken to CouchDB’s protocol. It would let datasets get updated in real time across the web. Imagine a set of scrapers on ScraperWiki automatically updating a visualisation on Many Eyes as the data changed.
Later even more imaginative things… I reckon Google’s Web Intents can be used to make the whole experience of the user slick when using multiple DMS’s at once. And hopefully somebody, somewhere is making a simplified version of SPARQL/RDF just as XML simplified SGML and then really took off.
Enough of me! What do you think?
Join in. Make standards. Write code.
Leave a comment below, and join the data protocols list.
Reblogged this on Things I grab, motley collection .
The argument is nice, but flawed. The analogy is not a cms, but something of more specific appeal such as A freedom of information request management system.
Most will be terrible, most focussed internally, and generally won’t spit out easily the thing you’re interested in today only.
But it’s a lot better than nothing for the majority of the task.
You should add Socrata to your list
Tom – Yes! I’ve now added them to the Wikipedia article http://en.wikipedia.org/wiki/Data_management_system#List_of_DMSs and referenced it with a Quora answer where Kevin Merritt, CEO of Socrata, draws a diagram showing Socrata as a datahub.
Didn’t this start with Gapminder (Gapminder.org) – the clever bit of which is now owned by Google.
The underlying technology, in my mind, ought to be topic maps, which is used in knowledge management (cf. ‘The tao of topic maps’ at http://www.ontopia.net/topicmaps/materials/tao.html ). The reason is quite simple, its not the data itself which is interesting, so much as the connections between data. Topic maps describe individual bits of data (topics) as well at the associations that data has with other data. Its these relationships that you really want to know about. Since Topic Maps have a defined query language, using them is relatively easy.
One of the most useful things you can do with topic maps is merge them. Basically it lets you combine the knowledge of a number of disparate sources and because there is also a mechanism for establishing identity (so the topic for London in Ontario, Canada is not confused with London in Britain) the merging is meaningful. You might have a topic map about Italian Opera and I might have a topic map about historical populations and disease and when you merge the two, you suddenly know that at the time when Puccini wrote some opera in Vienna, the population dropped 90% from the previous year due to an outbreak of hangnails.
Play around with a good topic map browser at http://www.ontopia.net/omnigator/models/index.jsp.