On-line directory tree webscraping
As you surf around the internet — particularly in the old days — you may have seen web-pages like this:
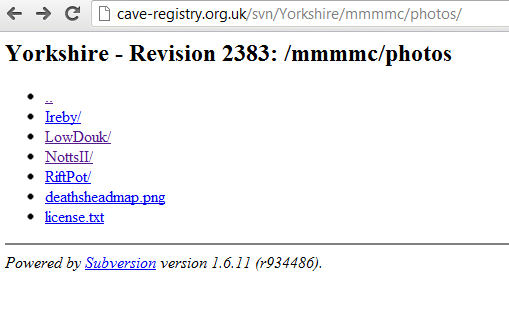
or this:
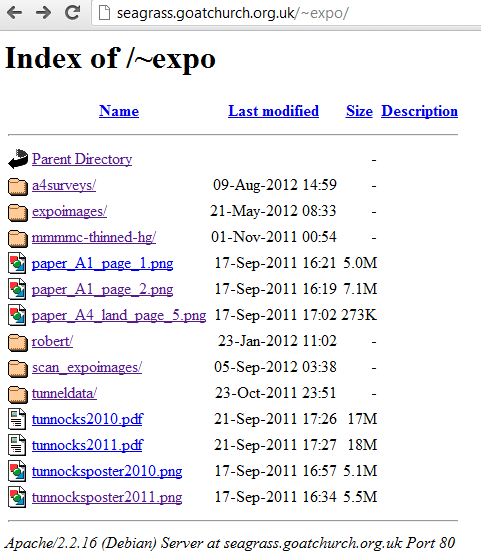
The former image is generated by Apache SVN server, and the latter is the plain directory view generated for UserDir on Apache.
In both cases you have a very primitive page that allows you to surf up and down the directory tree of the resource (either the SVN repository or a directory file system) and select links to resources that correspond to particular files.
Now, a file system can be thought of as a simple key-value store for these resources burdened by an awkward set of conventions for listing the keys where you keep being obstructed by the ‘/‘ character.
My objective is to provide a module that makes it easy to iterate through these directory trees and produce a flat table with the following helpful entries:
| abspath | fname | name | ext | svnrepo | rev | url |
|---|---|---|---|---|---|---|
| /Charterhouse/ 2010/ PotOxbow/ PocketTopoFiles/ | PocketTopoFiles/ | PocketTopoFile | / | CheddarCatchment | 19 | http://www.cave-registry.org.uk/ svn/ CheddarCatchment/ Charterhouse/ 2010/ PotOxbow/ PocketTopoFiles/ |
| /mmmmc/ rawscans/ MossdaleCaverns/ PolishedFloor-drawnup1of3.jpg | PolishedFloor-drawnup1of3.jpg | PolishedFloor-drawnup1of3 | .jpg | Yorkshire | 2383 | http://cave-registry.org.uk/svn/ Yorkshire/ mmmmc/ rawscans/ MossdaleCaverns/ PolishedFloor-drawnup1of3.jpg |
{kind=link}
Although there is clearly redundant data between the fields url, abspath, fname, name, ext, having them in there makes it much easier to build a useful front end.
The function code (which I won’t copy in here) is at https://scraperwiki.com/scrapers/apache_directory_tree_extractor/. This contains the functions ParseSVNRevPage(url) and ParseSVNRevPageTree(url), both of which return dicts of the form:
{'url', 'rev', 'dirname', 'svnrepo',
'contents':[{'url', 'abspath', 'fname', 'name', 'ext'}]}
I haven’t written the code for parsing the Apache Directory view yet, but for now we have something we can use.
I scraped the UK Cave Data Registry with this scraper which simply applies the ParseSVNRevPageTree() function to each of the links and glues the output into a flat array before saving it:
lrdata = ParseSVNRevPageTree(href) ldata = [ ] for cres in lrdata["contents"]: cres["svnrepo"], cres["rev"] = lrdata["svnrepo"], lrdata["rev"] ldata.append(cres) scraperwiki.sqlite.save(["svnrepo", "rev", "abspath"], ldata)
Now that we have a large table of links, we can make the cave image file viewer based on the query:
select abspath, url, svnrepo from swdata where ext=’.jpg’ order by abspath limit 500
By clicking on a reference to a jpg resource on the left, you can preview what it looks like on the right.
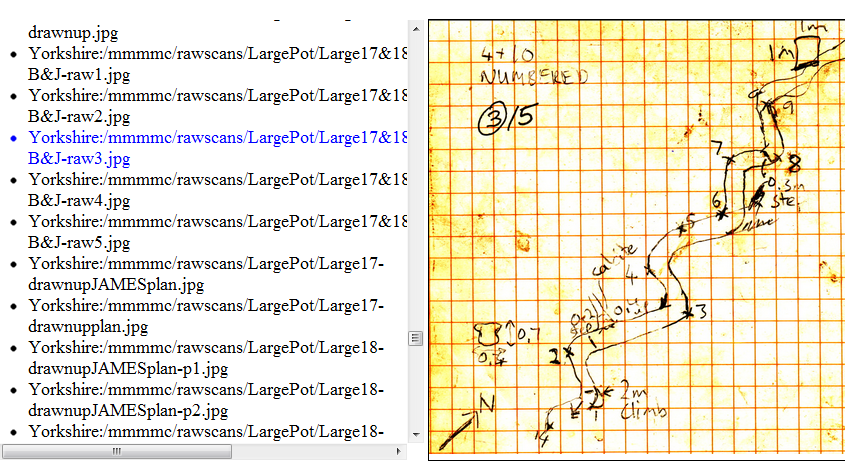
If you want to know why the page is muddy, a video of the conditions in which the data was gathered is here.
Image files are usually the most immediately interesting out of any unknown file system dump. And they can be made more interesting by associating meta-data with them (given that no convention for including interesting information in the EXIF sections of their file formats). This meta-data might be floating around in other files dumped into the same repository — eg in the form of links to them from html pages which relate to picture captions.
But that is a future scraping project for another time.
Or just