The next evolution of ScraperWiki
Quietly, over the last few months, we’ve been rebuilding both the backend and the frontend of ScraperWiki.
The new ScraperWiki has been built from the ground up to be more powerful for data scientists, and easier to use for everyone else. At its core, it’s about empowering people to take a hold of their data, to analyse it, combine it, and make value from it.
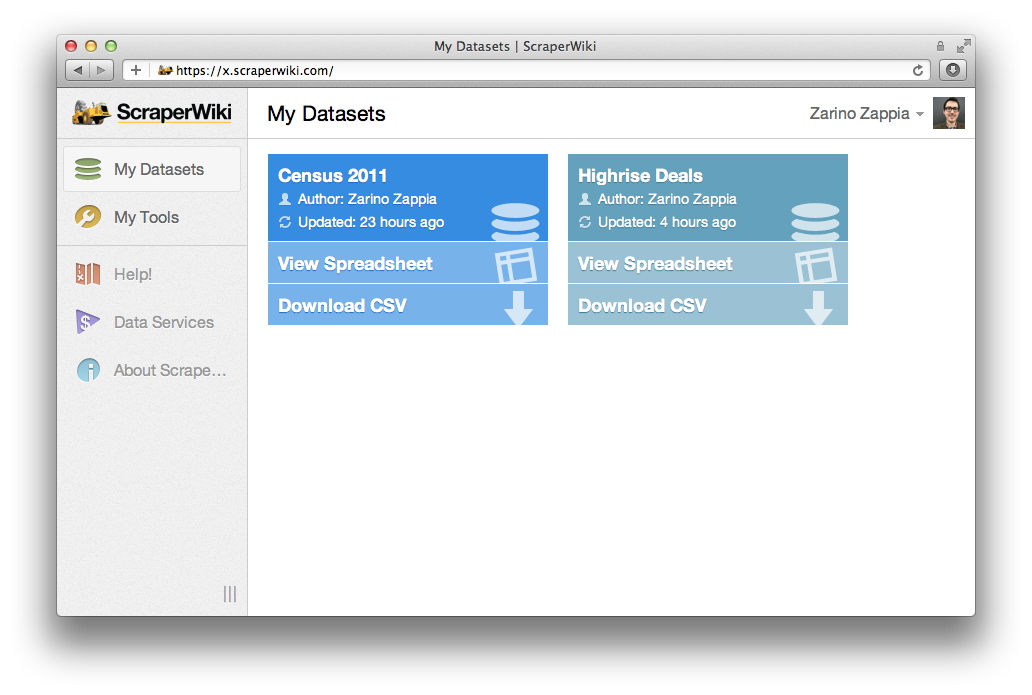
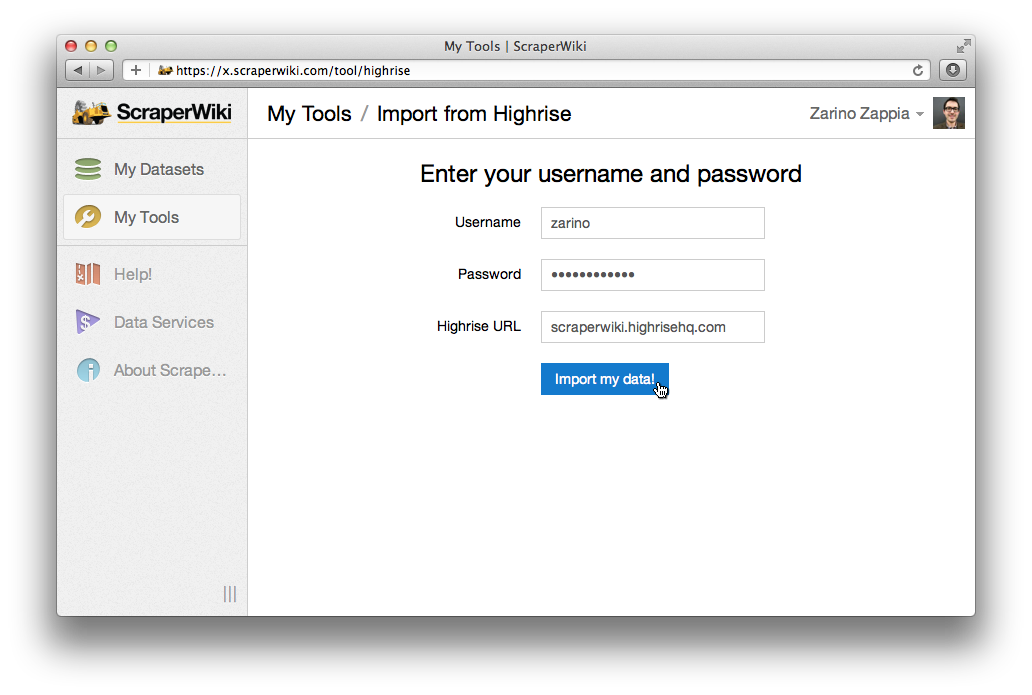
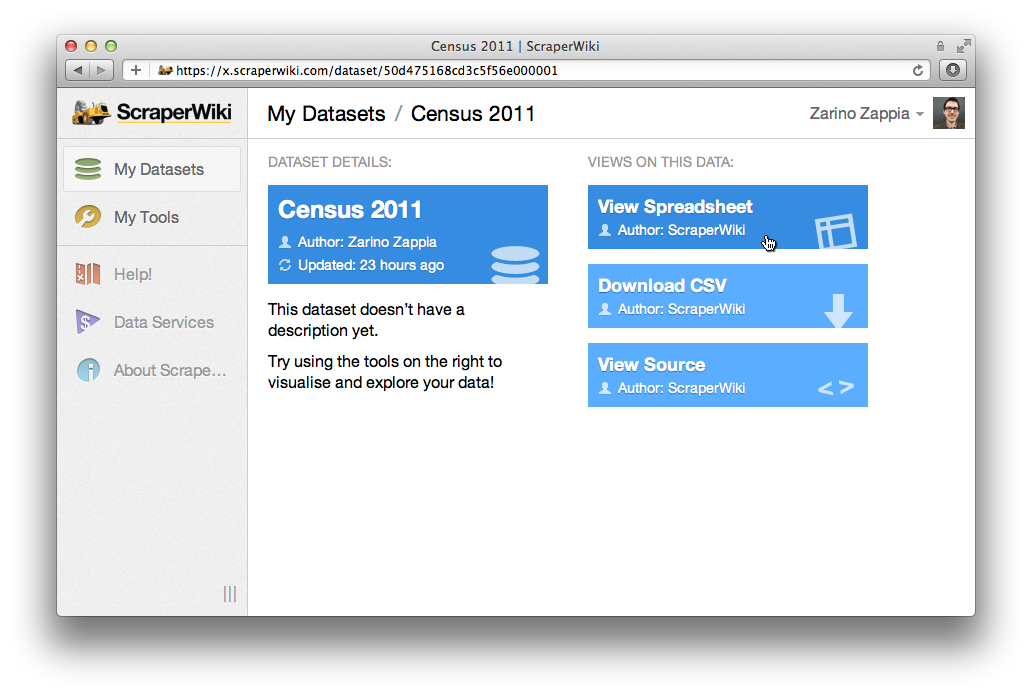
We can’t wait to let you try it in January. In the meantime, however, we’re pleased to announce that all of our corporate customers are already migrating to the new ScraperWiki for scraping, storing and visualising their private datasets.
If you want data scraping, cleaning or analysing, then you can join them. Please get in touch. We’ve got a data hub and a team of data scientists itching to help.
I like the new design. It give a metro-like feel.
Visualization is the feature I always wanting. When this expecting to completely deploy to users?
Firdaus – initial version in January. It’ll really show itself as the tools mature over the months after that.
Is the new backend functional now? If not, what’s the ETA? Can we expect scrapers to run at the scheduled time rather than how it was sometimes with the old one?
The new platform’s largely functional, and is being used by our Data Services customers and a handful of beta testers. Getting it ready for public release has taken a little longer than anticipated, but we’re keen to get it into our users’ hands ASAP. Watch this space 🙂
Also, if you’d like to be in our next group of beta testers, and get early access (albeit with some rough edges!) let me know.
And yes, the new platform uses Cron to schedule tasks, so code runs at an exact time, as you’d expect.