Hip Data Terms
“Big Data” and “Data Science” tend to be terms whose meaning is defined the moment they are used. They are sometimes meaningful, but their meaning is dependent on context. Through the agendas of many hip and not-so-hip data talks we could come up with some definitions some people mean, and will try and describe how big data and data science are used now.
Big data
When some people say big data, they are describing something physically big—in terms of bytes. So a petabyte of data would be big, at least today. Other people think of big data in terms of thresholds of big. So if data don’t fit into random-access memory, or cannot be stored on a single hard-drive, they’re talking about big data. More generally, we might say that if the data can’t be accessed by Excel (the world’s standard data analysis tool), it is certainly big, and you need to know something more about computing in order to store and access the data. Judging data-bigness by physical size sometimes works today. But sizes that seem big today are different from what seemed big twenty years ago and from what will seem big in twenty years. Lets look more at two descriptions of big data that get to the causes of data-bigness. One presenter at Strata London 2012 proposed that big data comes about when it becomes less expensive to store data than to decide about whether or not to delete it. Filing cabinets and libraries are giving way to Hadoop clusters and low-power hard drives, so it has become recently reasonable to just save anything. The second thing to look at is where all of this data comes from. Part of this big data thing is that we can now collect much more data automatically. Before computers, if the post office wanted to study where mail is sent, it could sample letters at various points and record their destinations, return addresses, and routes. Today we already have all our emails, Twitter posts and other correspondence in reasonably standard formats. So, this process is far more automatic, and we can collect much more data.
Data science
So, what is ‘data science’? It broadly seems to be some combination of ‘statistics’ and ‘computer engineering’. They’re in quotes because these categories are ambiguous and because they are difficult to define except in terms of one another. Let’s define ‘data science’ by relating it to ‘statistics’ and ‘software engineering’, and we’ll start with statistics.
‘Data science’ and ‘statistics’
First off, the statistical methods used in ‘data science’ and ‘big data’ seem quite unsophisticated compared to those used in ‘statistics’. Often, it’s just search. For example, the data team at La Nación demonstrated how they’re acquiring loads of documents and allowing journalists to search them. Certainly, they will eventually start doing crude quantitative analyses on the overall document sets, but even the search has already been valuable. Their team pulls in another hip term: ‘data journalism’. Quantitative analyses that do happen are often quite simple. Consider the FourSquare checkin analyses that a couple people from FourSquare demoed at DataGotham. The demo mostly comprised scatterplots of checkins on top of a map, and sometimes it played over time. They touched on the models they were using to guess where someone wanted to check in, but they emphasised the knowledge gained from looking at checkin histories, and these simple plots were helpful for conveying this. In other cases, ‘data science’ simply implies ‘machine learning’. Compared to ‘statistics’, ‘machine learning,’ though, implies a focus on prediction rather than inference. Statisticians seem to make use of more complex models on simpler datasets, and are more concerned with consuming and applying data than they are with the modelling of the data.
‘Data science’ and ‘software engineering’
The products of ‘software engineering’ tend to be tools, and the products of ‘data science’ tend to be knowledge. We can break that distinction into some components for illustration. (NB: These components exaggerate the differences.)
Realtime v. batch: If something is ‘realtime’, it is the result of ‘software engineering’; ‘data science’ is usually done in batches. (Let’s avoid worrying too much about what ‘realtime’ means. We could take ‘realtime’ to mean push rather than pull, and that could work for a reasonable definition of ‘realtime’.)
Organization: ‘Data scientists’ are embedded within organizations that have questions about data (typically about their own data, though that depends on how we think of ownership). Consider any hip web startup with a large database. ‘Software engineers’, on the other hand, make products to be used by other organizations or by other departments within a large organization. Consider any hip web startup ever. Also consider some teams within large companies; I know someone who worked at Google as a ‘software engineer’ to write code for packaging ChromeBooks.
What about ‘analysts’?
If we simplify the world to a two-dimensional space, ‘data scientists’, ‘statisticians’, ‘software engineers’, (This chart uses ‘developer’. Oops.) ‘engineers’ might land here.
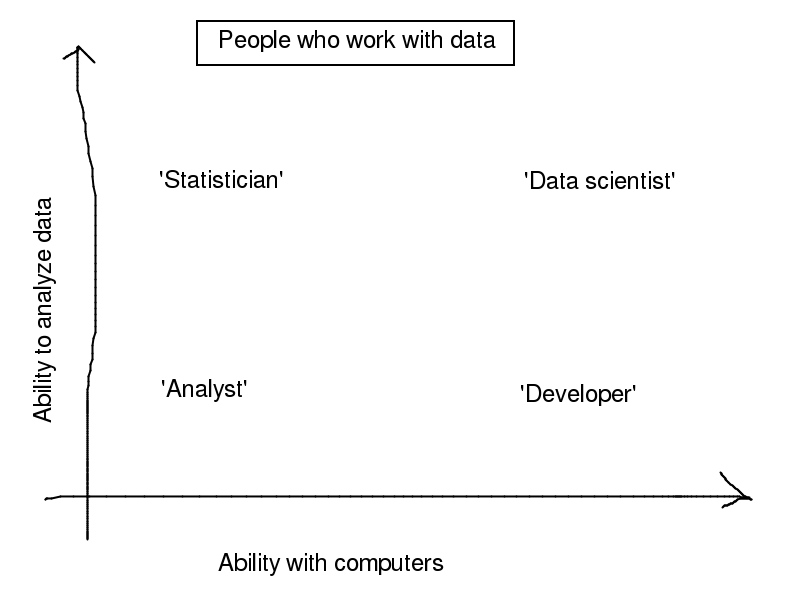
Conflating ‘data science’ and ‘big data’
Some people conflate ‘data science’ and ‘big data’. For some definitions of these two phrases, the conflation makes perfect sense, like when ‘big data’ means that the data are big enough that you need to know something about computers. Some people are more concerned with ‘data science’ than they are with ‘big data’, and vice-versa. For example, ‘big data’ is much talked-about at Strata, but ‘data science’ isn’t discussed as much. Perhaps ‘big data’ is buzzier and more popular among the marketing departments? To other people, ‘data science’ is more common, and this is in part to emphasise the fact that they can do useful things with small datasets too. It might be that we want some word to describe what we do. ‘Statistician’ and ‘software developer’ aren’t close enough, but ‘data scientist’ is decent.
Utility of these definitions
Consider taking this post with a grain of salt. Some definitions may be more clear to one group of people than to another, and they may be over-simplified here. On the other hand, these definitions are intended be descriptive rather than prescriptive, so they might be more useful than some other definitions that you’ve heard. No matter how you define a hip or un-hip term, it is impossible to avoid all ambiguities.
Trackbacks/Pingbacks
[…] about people outside the ScraperWiki office? Data superhero and wearer of pink hats, Tom Levine, once wrote about how data scientists are basically a cross between statisticians and programmers. Would they […]