Combining survey data with scraped data to tell a story
Guest post by Dan Armstrong
 My last three jobs have involved telling stories with survey data. Since every story requires a conflict, I look for conflicts. For instance, I’ll go to CFOs and ask them if their marketing people are doing a good job. Then I’ll ask the marketers if they think they’re doing a good job. Here’s a surprise: They don’t agree. And therein lies a story.
My last three jobs have involved telling stories with survey data. Since every story requires a conflict, I look for conflicts. For instance, I’ll go to CFOs and ask them if their marketing people are doing a good job. Then I’ll ask the marketers if they think they’re doing a good job. Here’s a surprise: They don’t agree. And therein lies a story.
One way I’ve been able to uncover stories is to compare what people tell me with other data that they don’t tell me. That’s where Scraperwiki comes in. There’s a lot of company information available on sites ranging from EDGAR to Wikipedia to Yahoo Finance. It’s all public. You can buy it from people who aggregate and repackage it. Or you can scrape it. I choose the latter.
In my current job at ITSMA—the IT Services Marketing Association—we did a brand awareness survey of buyers of IT services. We asked them: “Which companies come to mind when you think of technology consulting and services?” The executives named 49 companies more than once. We tracked the percentage of mentions that each company received, which ranged from 52% (for IBM) to only one mention (114 companies). (Nobody mentioned Scraperwiki, but I’m confident that they will next year.)
What drives brand awareness? It’s partly how much the company spends to promote itself. But it’s mostly size, usually measured as number of employees, market capitalization or annual revenue. So I collected the ticker symbols of the companies mentioned by our survey respondents and wrote a scraper (with the help of the good people on the Scraperwiki Google Group) to collect data on company size. I chose to go to Yahoo Finance because the page layout there is easy to parse, and the URLs are based on ticker symbols. The most recent version of the scraper is at https://scraperwiki.com/scrapers/yahoo_finance_company_info/.
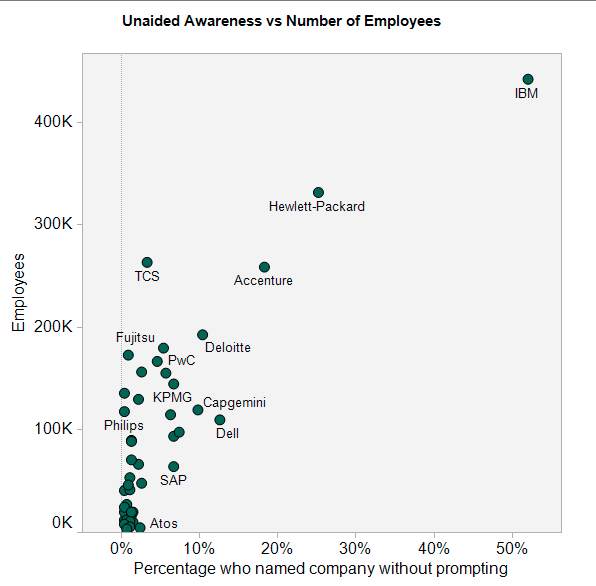
I found that the company size variable most closely correlated with brand awareness was the number of professionals available to take on large-scale projects. Clearly there’s a power law at work: a handful of companies with very high brand awareness and a “long tail” of firms that are barely on the radar.
As the chart (created using Tableau) shows, this pattern mirrors another dynamic: the fact that there are a few very big companies and many small ones. Brand perceptions reflect the underlying reality of company size.
My next project will be to scrape the ages of CEOs to update this age distribution from a few years back: http://www.analyzethis.net/2009/11/30/the-93-year-old-ceo/ (The oldest CEO, Walter Zable, died last year at the age of 97.) The age data is all there on Yahoo Finance. It’s going to take some regular expressions to get at it. But I’m confident there will be a story in the results.
You can catch Dan on twitter via @ITSMA_B2B, or post feedback, suggestions and ideas to him on the ScraperWiki Group.
Yahoo FInance provides APIs to access their data. They do this to prevent you from wasting your time and bandwidth (as well as their own.) In the future you might try to discover if the data has already been made publicly available before resorting to scraping.
Yes, in the future I might want to do that, as you say. Always good to learn something new. I’ll look into the API.
Dan
OK, I looked into the Yahoo Finance API. It covers some data, like stock prices and daily trade volume. Not the kind of thing I need, which is descriptive data about particular companies – number of employees, market cap, location, revenue, stuff like that. Thanks for the suggestion, though.
“What drives brand awareness? It’s partly how much the company spends to promote itself. But it’s mostly size, usually measured as number of employees, market capitalization or annual revenue.”
–Can you find correlations between company size and how much the company spends to promote itself? e.g. Does IBM (the largest) spend less on marketing than, say, Deloitte? Because that would open other all sorts of other stories.
Yes, in the future I might want to do that, as you say. I’ll look into learning how to access the data via the API. Thanks for the tip.
Dan