Asking data questions of words
The vast majority of my contributions to the web have been loosely encoded in the varyingly standard-compliant family of languages called English. It’s a powerful language for expressing meaning, but the inference engines needed to parse it are pretty complex, staggeringly ancient, yet cutting edge (i.e. brains). We tend to think about data a lot at ScraperWiki, so I wanted to explore how I can ask data questions of words.
Different engines render English into browser-viewable markup (HTML): twitter, wordpress, Facebook, tumblr and emails; alongside various iterations of employers’ sites, industry magazines, and short notes on things I’ve bought on Amazon. Much of this is scrapeable or available via APIs, and a lot of ScraperWiki’s data science work has been gathering, cleaning, and analysing data from websites.
For sharing facts as data, people publish CSVs, tables and even occasionally access to databases, but I think there are lessons to learn from the web’s primary, human-encoded content. I’ll share my first tries, and hope to get some feedback (comment below, or drop me a line on the Scraperwiki Google Group, please).
NLTK
There’s a particularly handy Python package for treating words as data, and the people behind NLTK wrote a book (available online) introducing people not only to the code package, but to ways of thinking programmatically about language.
One of many nice things about NLTK is that it gives you loads of straightforward functions so you can put names to different ways of slicing up and comparing your words. To get started, I needed some data words. I happened to have a collection of CSV files containing my archive of tweets, and the ever-helpful Dragon at ScraperWiki helped me convert all these files into one long text doc, which I’m calling my twitter corpus.
Then, I fed NLTK my tweets and gave it a bunch of handles – variables – on which I may want to tug in future, (mainly to see what they do).
[sourcecode language=”python”]
from nltk import *
filename = ‘tweets.txt’
def txt_to_nltk(filename):
raw = open(filename, ‘rU’).read()
tokens = word_tokenize(raw)
words = [w.lower() for w in tokens]
vocab = sorted(set(words))
cleaner_tokens = wordpunct_tokenize(raw)
# “Text” is a datatype in NLTK
tweets = Text(tokens)
# For language nerds, you can tag the Parts of Speech!
tagged = pos_tag(cleaner_tokens)
return dict(
raw = raw,
tokens = tokens,
words = words,
vocab = vocab,
cleaner_tokens = cleaner_tokens,
tweets = tweets,
tagged = tagged
)
tweet_corpus = txt_to_nltk(filename)
[/sourcecode]
Following some exercises in the book, I jumped straight to the visualisations. I asked for a lexical dispersion plot of some words I assumed I must have tweeted about. The plot illustrates the occurrence of words within the text. Because my corpus is laid-out chronologically (the beginning of the text is older than the end), I assumed I would see some differences over time:
[sourcecode language=”python”]
tweet_corpus.dispersion_plot([“coffee”, “Shropshire”, “Yorkshire”,
“cycling”, “Tramadol”])
[/sourcecode]
Can you guess what some of them might be?
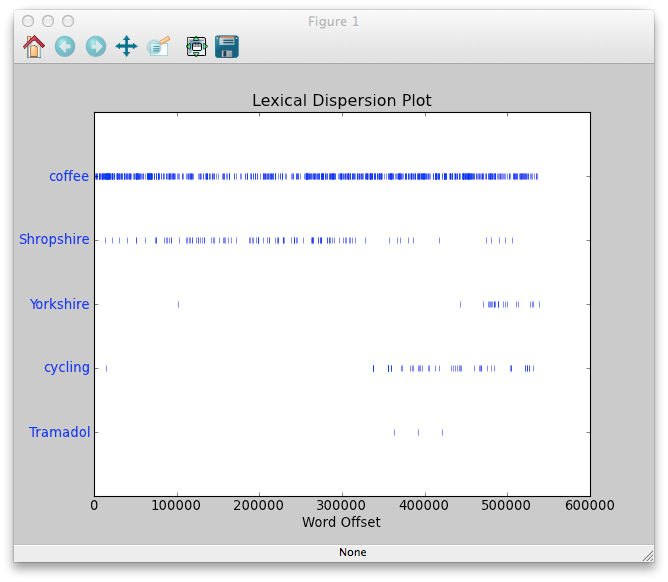
This ended up pretty much as I’d expected: illustrating my move from Shropshire to Yorkshire. It shows when I started tweeting about cycling, and the lovely time I ended up needing to talk about powerful painkillers (yep, that’s related to cycling!). I continuously cover the word “coffee” in my tweets. This kind of visualisation could be particularly useful for marketers watching the evolution of keywords, or head-hunters keeping an eye out for emerging skills. Basically, anyone who wants to see when a topic gathers reference within a set of words (e.g. the back-catalog of an industry blog).
Alongside the lexical dispersion plot, I also wanted to focus on a few particular words within my tweets. I looked into how I tweet about coffee, and used a few of NLTK’s most basic functions. A simple: ‘tweet_corpus.count(“coffee”)’, for example, gives me the beginnings of keyword metrics from my social media. (I’ve tweeted “coffee” 809 times, btw.) Using the vocab variable, I can ask Python – ‘len(vocab)’ – how many different words I use (around 35k), though this tends to include some redundancies like plurals and punctuation. Taking an old linguist’s standby, I also created a concordance, getting the occurrences within context. NLTK beautifully lined this all up for me with a single command: ‘tweetcorpus.concordance(“coffee”)’
I could continue to walk through other NLTK exercises, showing you how I built bigrams and compared words, but I’ll leave further exploration for future posts.
What I would like to end with is an observation/question: this noodling in the natural language processing on social data makes it clear that a very few commands can be used to provide context and usage metrics for keywords. In other words, it isn’t very hard to see how often you’ve said (in this case tweeted) a keyword you may be tracking. You could treat just about any collection of words as your own corpus (company blog, user manuals, other social media…), and start asking some very straightforward questions very quickly.
What other data questions would you want to ask of your words?