Testing, testing…
 Data science is a distinct profession from software engineering. Data scientists may write a lot of computer code but the aim of their code is to answer questions about data. Sometimes they might want to expose the analysis software they have written to others in order they can answer questions for themselves, and this is where the pain starts. This is because writing code that only you will use and writing code someone else will use can be quite different.
Data science is a distinct profession from software engineering. Data scientists may write a lot of computer code but the aim of their code is to answer questions about data. Sometimes they might want to expose the analysis software they have written to others in order they can answer questions for themselves, and this is where the pain starts. This is because writing code that only you will use and writing code someone else will use can be quite different.
ScraperWiki is a mixed environment, it contains people with a background in software engineering and those with a background in data analysis, like myself. Left to my own devices I will write code that simply does the analysis required. What it lacks is engineering. This might show up in its responses to the unexpected, its interactions with the user, its logical structure, or its reliability.
These shortcomings are addressed by good software engineering, an area of which I have theoretical knowledge but only sporadic implementation!
I was introduced to practical testing through pair programming: there were already tests in place for the code we were working on and we just ran them after each moderate chunk of code change. It was really easy. I was so excited by it that in the next session of pair programming, with someone else, it was me that suggested we added some tests!
My programming at ScraperWiki is typically in Python, for which there a number of useful testing tools. I typically work from Windows, using the Spyder IDE and I have a bash terminal window open to commit code to either BitBucket or Github. This second terminal turns out to be very handy for running tests.
Python has an internal testing mechanism called doctest which allows you to write tests into the top of a function in what looks like a comment. Typically these comprise a call to the function from a command prompt followed by the expected response. These tests are executed by running a command like:
python -m doctest yourfile.py
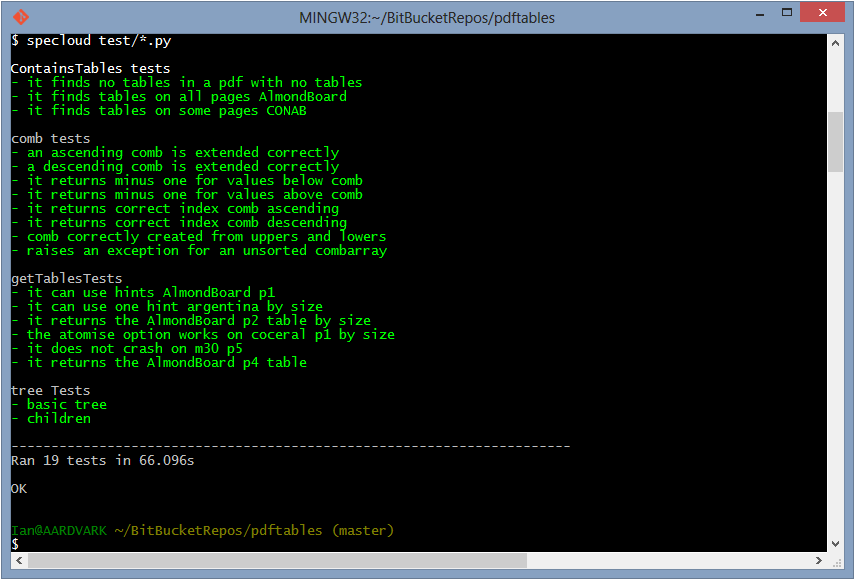
This is OK, and it’s “batteries included” but I find the mechanism a bit ugly. When you’re doing anything more complicated than testing inputs and outputs for individual functions, you want to use a more flexible mechanism like nose tools, with specloud to beautify the test output. The Git-Bash terminal on Windows needs a little shim in the form of ansicon to take full advantage of specloud’s features. Once you’re suitably tooled up, passed tests are marked with a vibrant, satisfying green and the failed tests by a dismal, uncomfortable red.
My latest project, a module which automatically extracts tables from PDF files, has testing. It divides into two categories: testing the overall functionality – handy as I fiddle with structure – and tests for mathematically or logically complex functions. In this second area I’ve started writing the tests before the functions, this is because often this type of function has a simple enough description and test case but implementation is a bit tricky. You can see the tests I have written for one of these functions here.
Testing isn’t as disruptive to my workflow as I thought it would be. Typically I would be repeatedly running my code as I explored my analysis making changes to a core pilot script. Using testing I can use multiple pilot scripts each testing different parts of my code; I’m testing more of my code more often and I can undertake moderate changes to my code, safe in the knowledge that my tests will limit the chances of unintended consequences.