Making a ScraperWiki view with R
In a recent post I showed how to use the ScraperWiki Twitter Search Tool to capture tweets for analysis. I demonstrated this using a search on the #InspiringWomen hashtag, using Tableau to generate a visualisation.
Here I’m going to show a tool made using the R statistical programming language which can be used to view any Twitter Search dataset. R is very widely used in both academia and industry to carry out statistical analysis. It is open source and has a large community of users who are actively developing new libraries with new functionality.
Although this viewer is a trivial example, it can be used as a template for any other R-based viewer. To break the suspense this is what the output of the tool looks like:
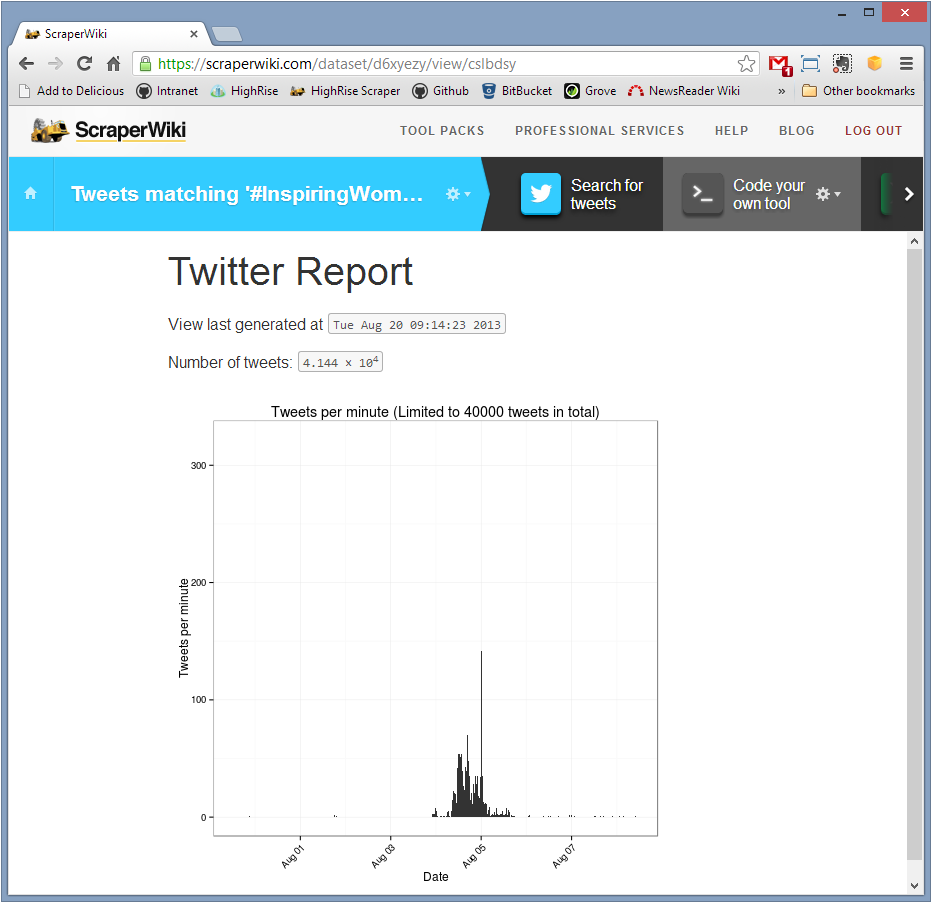
The tool updates when the underlying data is updated, the Twitter Search tool checks for new tweets on an hourly basis. The tool shows the number of tweets found and a histogram of the times at which they were tweeted. To limit the time taken to generate a view the number of tweets is limited to 40,000. The histogram uses bins of one minute, so the vertical axis shows tweets per minute.
The code can all be found in this BitBucket repository.
The viewer is based on the knitr package for R, which generates reports in specified formats (HTML, PDF etc) from a source template file which contains R commands which are executed to generate content. In this case we use Rhtml, rather than the alternative Markdown, which enables us to specify custom CSS and JavaScript to integrate with the ScraperWiki platform.
ScraperWiki tools live in their own UNIX accounts called “boxes”, the code for the tool lives in a subdirectory, ~/tool, and web content in the ~/http directory is displayed. In this project the http directory contains a short JavaScript file, code.js, which by the magic of jQuery and some messy bash shell commands, puts the URL of the SQL endpoint into a file in the box. It also runs a package installation script once after the tool is first installed, the only package not already installed is the ggplot2 package.
The ScraperWiki platform has an update hook, simply an executable file called update in the ~/tool/hooks/ directory which is executed when the underlying dataset changes.
This brings us to the meat of the viewer: the knitrview.R file calls the knitr package to take the view.Rhtml file and convert it into an index.html file in the http directory. The view.Rhtml file contains calls to some functions in R which are used to create the dynamic content.
Code for interacting with the ScraperWiki platform is in the scraperwiki_utils.R file, this contains:
- a function to read the SQL endpoint URL which is dumped into the box by some JavaScript used in the Rhtml template.
- a function to read the JSON output from the SQL endpoint – this is a little convoluted since R cannot natively use https, and solutions to read https are different on Windows and Linux platforms.
- a function to convert imported JSON dataframes to a clean dataframe. The data structure returned by the rjson package is comprised of lists of lists and requires reprocessing to the preferred vector based dataframe format.
Functions for generating the view elements are in view-source.R, this means that the R code embedded in the Rhtml template are simple function calls. The main plot is generated using the ggplot2 library.
So there you go – not the world’s most exciting tool but it shows the way to make live reports on the ScraperWiki platform using R. Extensions to this would be to allow some user interaction, for example by allowing them to adjust the axis limits. This could be done either using JavaScript and vanilla R or using Shiny.
What would you do with R in ScraperWiki? Let me know in the comments below or by email: ian@scraperwiki.com