Time to try Table Xtract
Getting data out of websites and PDFs has been a problem for years with the default solution being the prolific use of copy and paste.
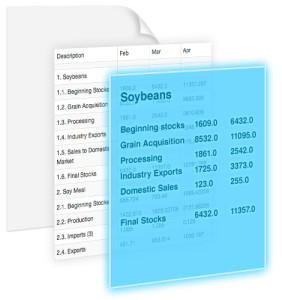 ScraperWiki has been working on a way to accurately extract tabular data from these sources and making it easy to export to Excel or CSV format. We have been internally testing and improving it with a seemingly infinite array of tables of different complexities. We’re now confident enough in Table Xtract’s accuracy that we are proud to put our name on it and launch a free beta version for you to try.
ScraperWiki has been working on a way to accurately extract tabular data from these sources and making it easy to export to Excel or CSV format. We have been internally testing and improving it with a seemingly infinite array of tables of different complexities. We’re now confident enough in Table Xtract’s accuracy that we are proud to put our name on it and launch a free beta version for you to try.
We are not stopping there though ,as many of you are asking for the ability to create datasets from multiple files/websites and more importantly, refresh them when the source files are updated. Look out for a Table Xtract Enterprise announcement soon!
Trackbacks/Pingbacks
[…] Getting data out of websites and PDFs has been a problem for years with the default solution being the prolific use of copy and paste. ScraperWiki has been working on a way to accurately extract ta… […]