A tool to help with your next job move
A guest post from Jyl Djumalieva.

Jyl Djumalieva
During February and March this year I had a wonderful opportunity to share the workspace with ScraperWiki team. As an aspiring data analyst, I found it very educational to learn how real-life data science happens. After observing ScraperWiki data scientist do some analytical heavy lifting I was inspired to embark on an exploratory analytics project of my own. This is what I’d like to talk about in this blog post.
The world of work has fundamentally changed: employees no longer grow via vertical promotions. Instead they develop transferable skills and learn new skills to reinvent their careers from time to time.
As people go through career transitions, they increasingly need tools that would help them make an informed choice on what opportunities to pursue. Imagine, if you were considering your career options, whether you would benefit from a high level overview of what jobs are available and where. To prioritize your choices and guide personal development, you might also want to know the average salary for a particular job, as well as skills and technology commonly used. In addition, perhaps you would appreciate insights on what jobs are related to your current position and could be your next move.
So, have tools that would meet all of these requirements previously existed? As far as I am aware: no. The good news is that there is a lot of job market information available. However, the challenge is that the actual job postings are not linked directly to job metadata (e.g. average salary, tools and technology used, key skills, and related occupations) This is why, as an aspiring data analyst, I have decided to bring the two sources of information together; you can find a merging of job postings with metadata demonstrated in the Tableau workbook here. For this purpose I have primarily used Python, publicly available data and Tableau Public, not to mention the excellent guidance of the ScraperWiki data science team.
The source of the actual job postings was the Indeed.com job board. I chose to use this site because it is an aggregator of job postings and includes vacancies from companies’ internal applicant tracking systems in addition to vacancies published on open job boards. The site also has an API, which allows to search job postings using multiple criteria and then retrieve results in an xml format. For this example, I used Indeed.com API to collect data for all job postings in the state of New York that were available on March 10, 2015. The script used to accomplish this task is posted to this bitbucket repository.
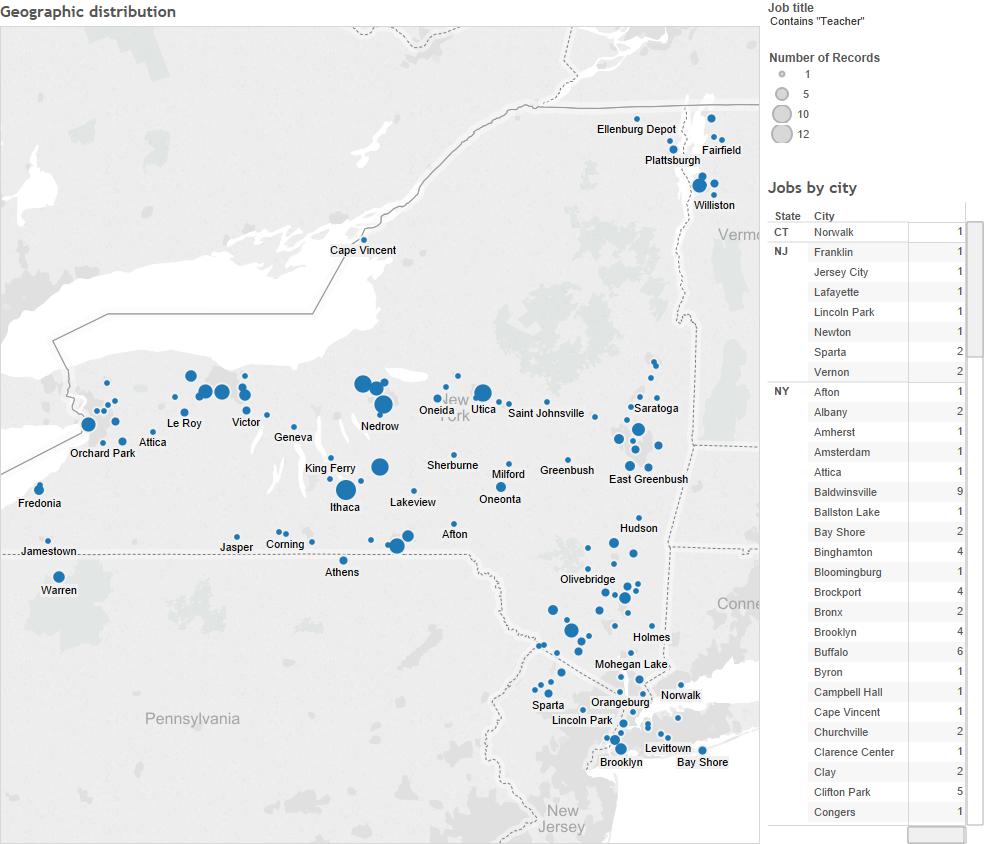
Teaching jobs from Indeed in New York State, February 2015
To put in place the second element of the project – job metadata – I have gathered information from O*NET, which stands for Occupational Information Network (O*NET) and is a valuable online source of occupational information. O*NET is implemented under the sponsorship of the US Department of Labor/Employment and Training Administration. O*NET provides API for accessing most of the aspects of each occupation, such as skills, knowledge, abilities, tasks, related jobs, etc. It’s also possible to scrape data on average reported wages for each occupation directly from the O*NET website.
So, at this point, we have two types of information: actual jobs postings and job metadata. However, we need to find a way to link these two to turn it into a useful analytical tool. This has proven to be the most challenging part of the project. The real world job titles are not always easily assigned to a particular occupation. For instance, what do “Closing Crew” employees do, or what is the actual occupation of an “IT Invoice Analyst?”
The process for dealing with this challenge included exact and fuzzy matching of actual job titles with previously reported job titles, and assigning an occupation based on a key word in a job title (e.g., “Registered nurse”). Fuzzy wuzzy python library was a great resource for this task. I intend to continue improving the accuracy and efficiency of the title matching algorithm.
After collecting, extracting and processing the data, the next step was to find a way to visualize it. Tableau Public turned out to be a suitable tool for this task and made it possible to “slice and dice” the data from a variety of perspectives. In the final workbook, the user can search the actual job postings for NY state as well as see the information on geographic location of the jobs, average annual and hourly wages, skills, tools and technology frequently used and related occupations.

Next move, tools and technologies from the Tableau tool
I encourage everyone who wants to understand what’s going on in their job sector to check my Tableau workbook and bitbucket repo out. Happy job transitioning!