Elasticsearch and elasticity: building a search for government documents

“Examining Clouds” by Kate Ter Harr, licensed under CC BY 2.0.
Based in Paris, the OECD is the Organisation for Economic Co-operation and Development. As the name suggests, the OECD’s job is to develop and promote new social and economic policies.
One part of their work is researching how open countries trade. Their view is that fewer trade barriers benefit consumers, through lower prices, and companies, through cost-cutting. By tracking how countries vary, they hope to give legislators the means to see how they can develop policies or negotiate with other countries to open trade further.
This is a huge undertaking.
Trade policies not only operate across countries, but also by industry. This process requires a team of experts to carry out the painstaking research and detective work to investigate current legislation.
Recently, they asked us for advice on how to make better use of the information available on government websites. A major problem they have is searching through large collections of document to find relevant legislation. Even very short sections may be crucial in establishing a country’s policy on a particular aspect of trade.
Searching for documents
One question we considered is: what options do they have to search within documents?
- Use a web search engine. If you want to find documents available on the web, search engines are the first tool of choice. Unfortunately, search engines are black boxes: you input a term and get results back without any knowledge of how those results were produced. For instance, there’s no way of knowing what documents might have been considered in any particular search. Personalised search also governs the results you actually see. One normal-looking search of a government site gave us a suspiciously low number of results on both Google and Bing. Though later searches found far more documents, this is illustrative of the problems of search engines for exhaustive searching.
- Use a site’s own search feature. This is more likely to give us access to all the documents available. But, every site has a different layout and there’s a lack of a unified user interface for searching across multiple sites at once. For a one-off search of documents, having to manually visit and search across several sites isn’t onerous. Repeating this for a large number of searches soon becomes very tedious.
- Build our own custom search tool. To do this, we need to collect all the documents from sites and store those in a database that we run. This way we know what we’ve collected, and we can design and implement searches according to what the OECD need.
Elasticsearch
Enter Elasticsearch: a database designed for full text search and one which seemed to fit our requirements.
Getting the data
To see how Elasticsearch might help the OECD, we collected several thousand government documents from one website.
We needed to do very little in the way of processing. First, we extracted text from each web page using Python’s lxml. Along with the URL and the page title, we then created structured documents (JSON) suitable for storing in Elasticsearch.
Running Elasticsearch and uploading documents
Running Elasticsearch is simple. Visit the release page, download the latest release and just start it running. One sensible thing to do out of the box is change the default cluster name — the default is just elasticsearch. Making sure Elasticsearch is firewalled off from the internet is another sensible precaution.
When you have it running, you can simply send documents to it for storage using a HTTP client like curl:
curl "http://localhost:localport/documents/document" -X POST -d @my_document.json
For the few thousand documents we had, this wasn’t sluggish at all, though it’s also possible to upload documents in bulk should this prove too slow.
Querying
Once we have documents stored, the next thing to do is query them!
Other than very basic queries, Elasticsearch queries are written in JSON, like the documents it stores, and there’s a wide variety of query types bundled into Elasticsearch.
Query JSON is not difficult to understand, but it can become tricky to read and write due to the Russian doll-like structure it quickly adopts. In Python, the addict library is a useful one for making it easier to more directly write queries out without getting lost inside an avalanche of {curly brackets}.
As a demo, we implemented a simple phrase matching search using the should keyword.
This allows combination of multiple phrases, favouring documents containing more matches. If we use this to search for, e.g. "immigration quota"+"work permit", the results will contain one or both of these phrases. However, results with both phrases are deemed more relevant.
The Elasticsearch Tool

With our tool, researchers can enter a search, and very quickly get back a list of URLs, document titles and a snippet of a matching part of the text.
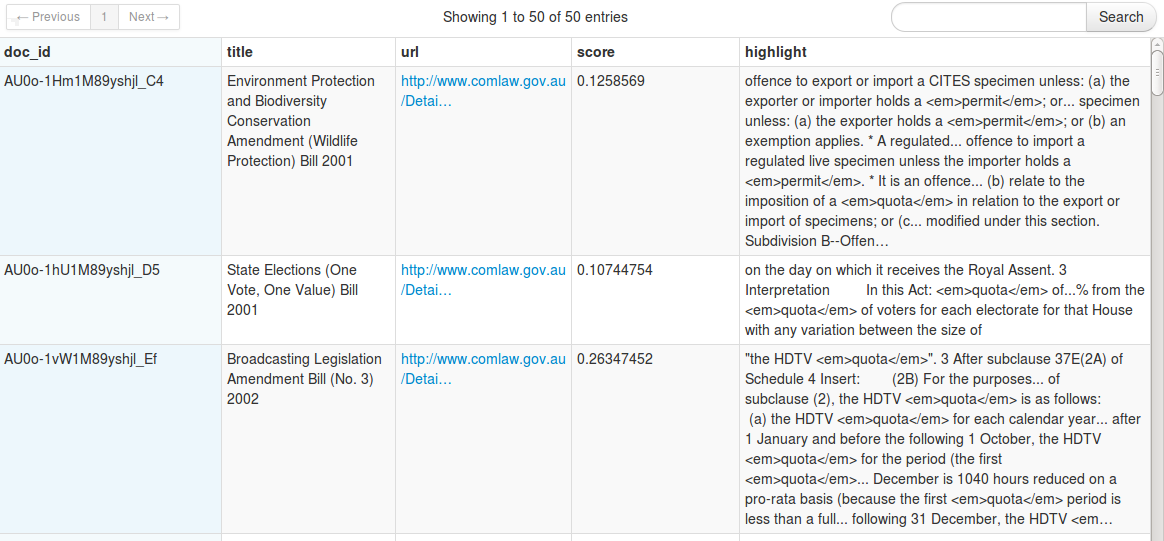
What we haven’t implemented is the possibility of automating queries which could also save the OECD a lot of time. Just as document upload is automated, we could run periodic keyword searches on our data. This way, Elasticsearch could be scheduled to lookout for phrases that we wish to track. From these results, we could generate a summary or report of the top matches which may prompt an interested researcher to investigate.
Future directions
For (admittedly small scale) searching, we had no problems with a single instance of Elasticsearch. To improve performance on bigger data sets, Elasticsearch also has built-in support for clustering, which looks straightforward to get running.
Clustering also ensures there is no single point of failure. However, there are known issues in that current versions of Elasticsearch can suffer document loss if nodes fail.
Provided Elasticsearch isn’t used as the only data store for documents, this is a less serious problem. It is possible to keep checking that all documents that should be in Elasticsearch are indeed there, and re-add them if not.
Elasticsearch is powerful, yet easy to get started with. For instance, its text analysis features support a large number of languages out of the box. This is important for the OECD who are looking at documents of international origin.
It’s definitely worth investigating if you’re working on a project that requires search. You may find that, having found Elasticsearch, you’re no longer searching for a solution.