Four specific things “agile” saved us from doing at ONS
There’s lots of both hype and cynicism around “agile”. Instead, look at this part of the original agile declaration.
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
… Responding to change over Following a plan
That is, while there is value in the items on the right, we value the items on the left more. (Source: The Agile Manifesto)
In this article, I’m going to give some concrete examples where this “flexible” aspect of agile saved us from doing unnecessary work.
The project is the Databaker project we have been working on with the Office for National Statistics. You can read a general introduction to the project on our blog.
Discovery phase
ScraperWiki does a Discovery phase as the first part of a project. This is usually time boxed, and small enough (5 to 20 days work) to easily and quickly get budget for. It gives an assessment of what technical solution will meet user needs, and what it will cost.
We met the ONS at csv,conf, where Dragon’s presentation on our open source spreadsheet-scraping library XYPath attracted their attention. So it was no surprise that our discovery report said:
In an ideal world this conversion process would be fully automated, however this is not possible with current technology.
This was the key simplification of the project. We made no attempt to use machine learning, or to build a fancy graphical interface – AI just isn’t good enough yet.
Instead, our solution was for the end user to learn a little bit of Python programming. To some, that appears to make their job harder. It doesn’t – complex technical user interfaces are very hard to learn. They’re also either expensive or impossible to make.
Here are the four things which at discovery we thought we’d have to do, but that we didn’t need to do in practice.
1. Running recipes
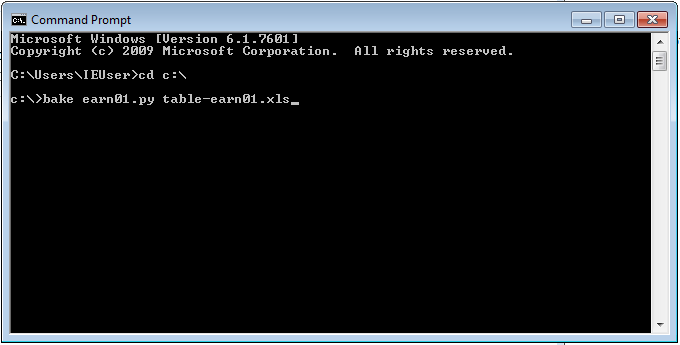 By the end of the second sprint, the customer was using the software to write and run recipes. They were using the initial command-line version of the tool.
By the end of the second sprint, the customer was using the software to write and run recipes. They were using the initial command-line version of the tool.
We’d thought that for ease of use under Windows we’d need to do slightly more than that – a lightweight GUI, or perhaps drag-and-drop integration into Explorer. This is what our discovery report said:
The graphical interface will also provide the ability to select recipe files and spreadsheet files, as well as reporting and logging conversion issues.
It turned out that ONS staff were more than happy with the command line. It worked, they understood it, and it let them script with batch files. Without this immediate feedback, we would have built something more, unnecessarily.
2. Editing recipes
 I don’t know where I got the idea that we’d need some kind of fancy editor integration. I think that much earlier I’d got overly excited about integrating the project into the ScraperWiki Data Science Platform.
I don’t know where I got the idea that we’d need some kind of fancy editor integration. I think that much earlier I’d got overly excited about integrating the project into the ScraperWiki Data Science Platform.
We spent a little bit of time during the project researching text editors. In the end though, the answer was super simple – just use Notepad++. Both our team and the ONS already used it. It’s free.
It wasn’t until I watched the customer install it on their system, and happily start using it for real work, that I properly understood that we just didn’t need anything else.
3. Debugging recipes
 We spent some time looking into different Python UI interface toolkits, and integrations between Excel and Python (xlwings, which was good but too slow), looking for a way to provide more debugging. Our discovery report said:
We spent some time looking into different Python UI interface toolkits, and integrations between Excel and Python (xlwings, which was good but too slow), looking for a way to provide more debugging. Our discovery report said:
An elaboration of this simplest tool is to provide a graphical interface which provides support to the user to write recipes by highlighting in a representation of the spreadsheet the cells selected by each line in a recipe.
Once again, the best answer was really simple – from Python generate spreadsheets with highlighting. No need for any new interface – Excel was the interface. No need for complex integration, Python can generate basic Excel files reliably. Simple to use, attractive, and very helpful for debugging.
We’d thought we might make something more interactive. Once again, actual delivery showed that this wasn’t a priority.
4. Installation
I was worried about installation at the start of the project. It was to be delivered on Windows, and as a company, ScraperWiki are used to delivering on the web. As individuals, we’d made installers for Windows before, but weren’t particularly looking forward to it.
Once again, the answer was to use something that already existed. The project is anyway open source. So we simply used the standard Python packaging system, PyPi.
 Combined with the fantastic Anaconda installer (I love Continuum Analytics!), we ended up with these installation and upgrade instructions.
Combined with the fantastic Anaconda installer (I love Continuum Analytics!), we ended up with these installation and upgrade instructions.
Not only are the instructions super short for the end user, they are also all the code for this part of the project (well, that and some PyPi configuration files we either had or would have needed anyway).
We couldn’t have planned this in advance, as we knew more about both the deployment environment and what we needed to deploy when we made the decision.
Benefits
What did all this time saving get spent on?
These more important things:
1) Dozens of tiny bugs and fixes to the recipe language to make it possible to convert more spreadsheets found in the wild.
2) Spending more time with the customer, both in formal training sessions, and informally, so they were using the software to deliver at maximum rate.
As a result the project was very successful – it finished on time and on budget. It delivered more value than we had hoped to deliver.