Which car should I (not) buy? Find out, with the ScraperWiki MOT website…
I am finishing up my MSc Data Science placement at ScraperWiki and, by extension, my MSc Data Science (Computing Specialism) programme at Lancaster University. My project was to build a website to enable users to investigate the MOT data. This week the result of that work, the ScraperWiki MOT website, went live. The aim of this post is to help you understand what goes on ‘behind the scenes’ as you use the website. The website, like most other web applications from ScraperWiki, is data-rich. This means that it is designed to give you facts and figures and provide an interface for you to interactively select and view data of your interest, in this case to query the UK MOT vehicle testing data.
The homepage provides the main query interface that allows you to select the car make (e.g. Ford) and model (e.g. Fiesta) you want to know about. 
You have the option to either view the top faults (failure modes) or the pass rate for the selected make and model. There is the option of “filter by year” which selects vehicles by the first year on the road in order to narrow down your search to particular model years (e.g. FORD FIESTA 2008 MODEL).
When you opt to view the pass rate, you get information about the pass rate of your selected make and model as shown:
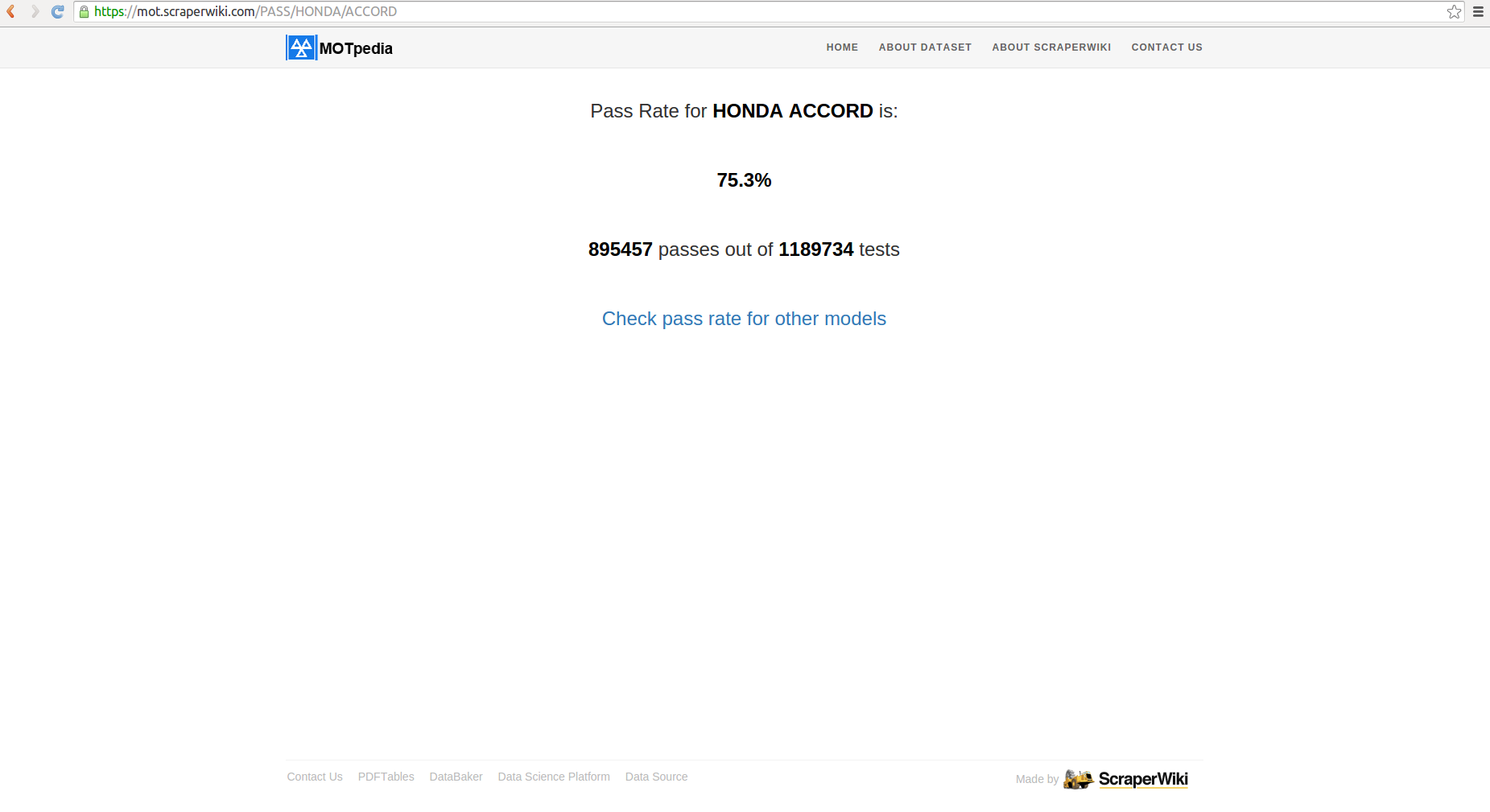
When you opt to view top faults you see the view below, which tells you the top 10 faults discovered for the selected car make and model with a visual representation.
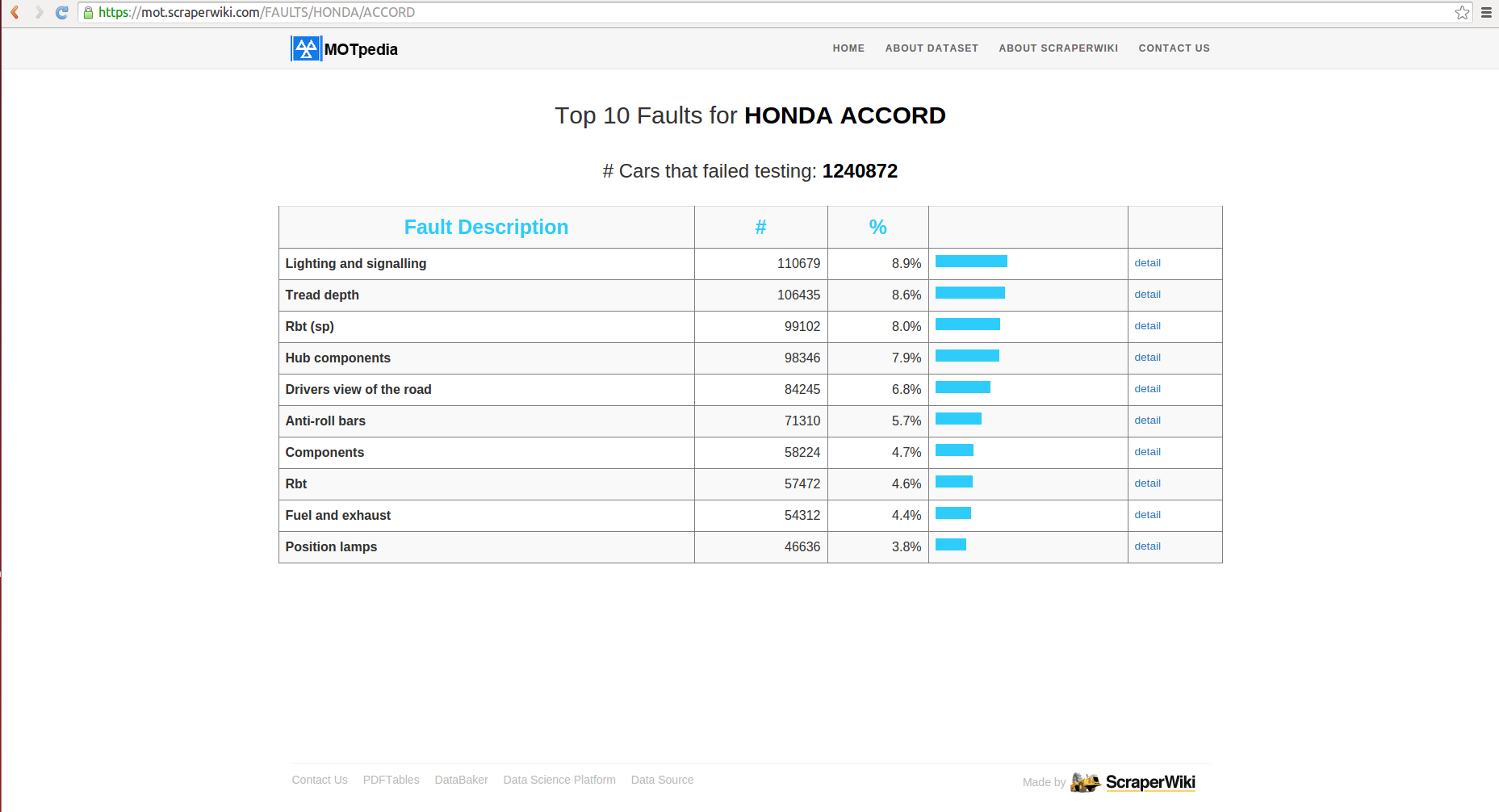
These are broad categorisations of the faults, if you wanted to break each down into more detailed descriptions, you click the ‘detail’ button:
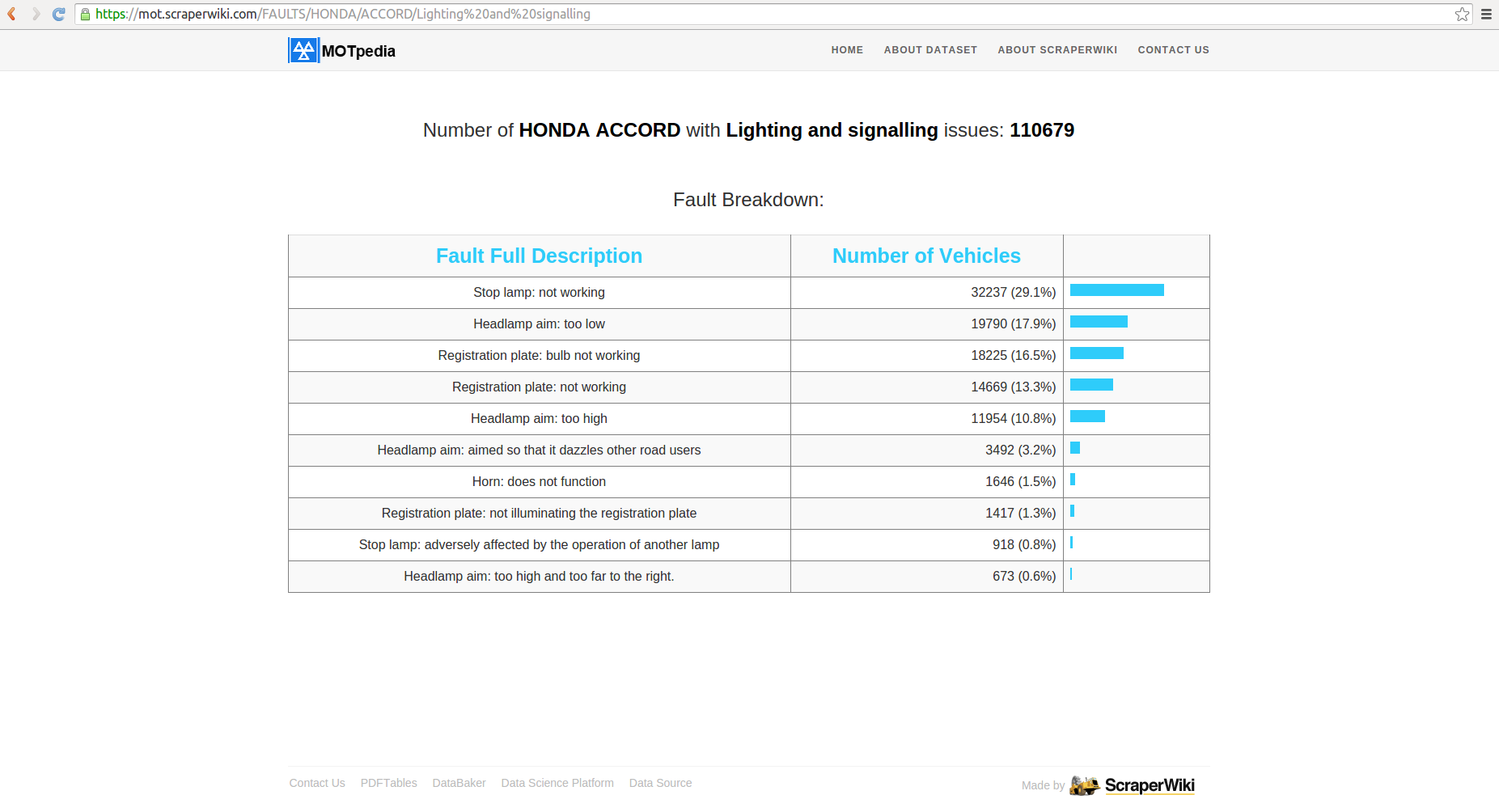
What is different about the ScraperWiki MOT website?
Many traditional websites use a database as a data source. While this is generally an effective strategy, there are certain disadvantages associated with this practice. The most prominent of which is that a database connection effectively has to always be maintained. In addition the retrieval of data from the database may take prohibitive amounts of time if it has not been optimised for the required queries. Furthermore, storing and indexing the data in a database may incur a significant storage overhead.
mot.scraperwiki.com, by contrast, uses a dictionary stored in memory as a data source. A dictionary is a data structure in Python similar to a hash-able map in Java. It consists of key-value pairs and is known to be efficient for fast lookups. But where do we get a dictionary from and what should be its structure? Let’s back up a little bit, maybe to the very beginning. The following general procedure was followed to get us to where we are with the data:
- 9 years of MOT data was downloaded and concatenated.
- Unix data manipulation functions (mostly command-line) were used to extract the columns of interest.
- Data was then loaded into a PostgreSQL database where data integration and analysis was carried out. This took the form of joining tables, grouping and aggregating the resulting data.
- The resulting aggregated data was exported to a text file.
The dictionary is built using this text file, which is permanently stored in an Amazon S3 bucket. The file contains columns including make, model, year, testresult and count. When the server running the website is initialised this text file is converted to a nested dictionary. That is to say a dictionary of dictionaries, the value associated with a key is another dictionary which can be accessed using a different key.
When you select a car make, this dictionary is queried to retrieve the models for you, and in turn, when you select the model, the dictionary gives you the available years. When you submit your selection, the computations of the top faults or pass rate are made on the dictionary. When you don’t select a specific year the data in the dictionary is aggregated across all years.
So this is how we end up not needing a database connection to run a data-rich website! The flip-side to this, of course, is that we must ensure that the machine hosting the website has enough memory to hold such a big data structure. Is it possible to fulfil this requirement at a sustainable, cost-effective rate? Yes, thanks to Amazon Web Services offerings.
So, as you enjoy using the website to become more informed about your current/future car, please keep in mind the description of what’s happening in the background.
Feel free to contact me, or ScraperWiki about this work and …enjoy!
Try our easy web interface over at PDFTables.com!