Highlights of 3 years of making an AI newsreader
We’ve spent three years working on a research and commercialisation project making natural language processing software to reconstruct chains of events from news stories, representing them as linked data.
If you haven’t heard of Newsreader before, our one year in blog post is a good place to start.
We recently had our final meeting in Luxembourg. Some highlights from the three years:
Papers: The academic partners have produced a barrage of papers. This constant, iterative improvement to knowledge of Natural Language Processing techniques is a key thing that comes out of research projects like this.
Open data: As an open data fan, I like some of the new components which will be of permanent use to anyone in NLP which came out of the project. For example, the MEANTIME corpus of news articles in multiple languages annotated with their events, for use in training.
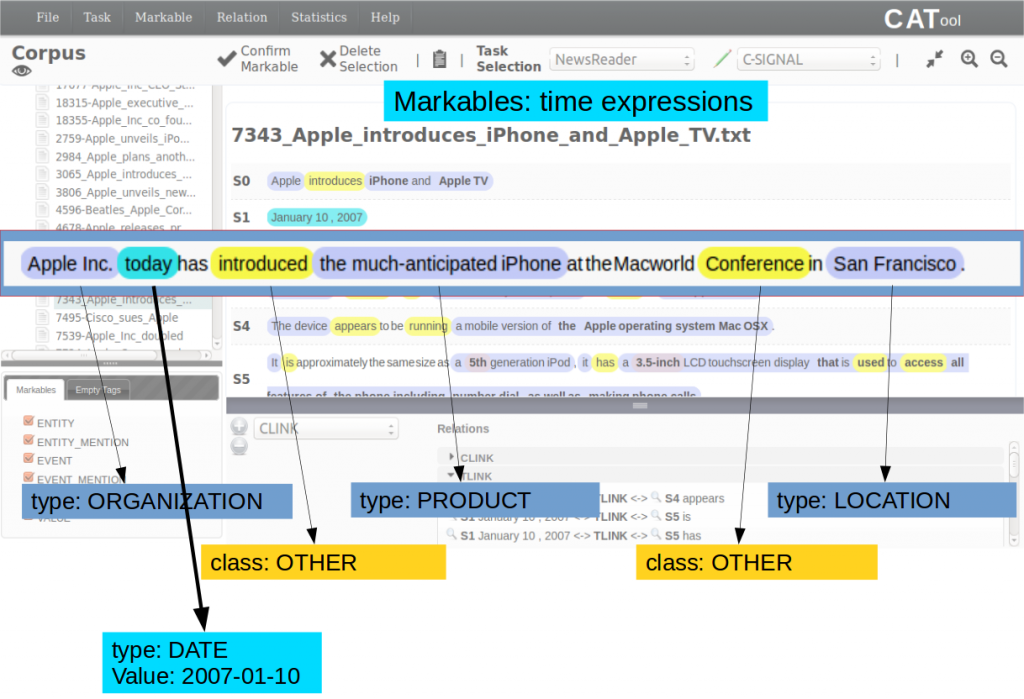
Open source: Likewise, as an open source fan, Newsreader’s policy was to produce open source software, and it made lots. As an example, the PIKES Knowledge Extraction Suite applies NLP tools to a text.
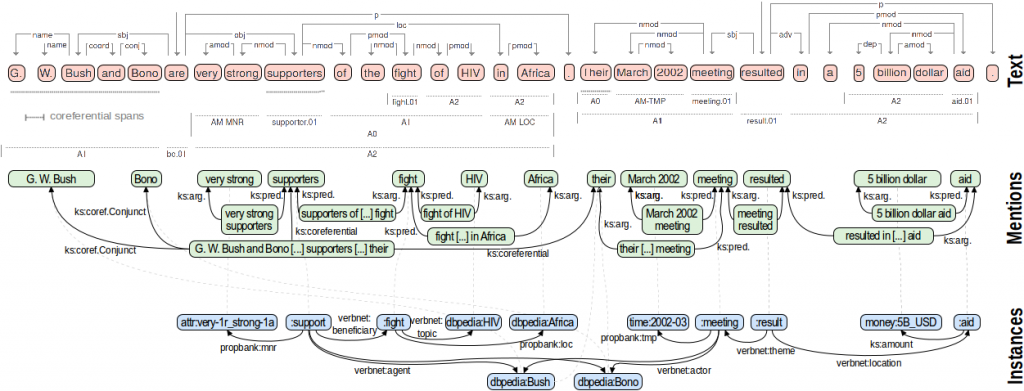
Exploitation: Is via integration into existing commercial products. All three commercial consortium members are working on this in some way (often confidentially for now). Originally at ScraperWiki, we thought it might plug into our PDFTables with additional natural language processing.
Simple API: A key part of our work was developing the Simple API, making the underlying SPARQL database of news events acccessible to hackers via a simpler REST API. This was vital for the Hackdays, and making the technology more accessible.
Hackdays: We ran several across the course of the project (example). They were great fun, working on World Cup and automotive related news article datasets, drawing a range of people from students to businesses.
Thanks Newsreader for a great project!
Together, we improved the quality of news data extraction, began the process of assembling that into events, and made steps towards commercialisation.