We’ve just rolled out a change to make our OData endpoint much faster. For example, it is down from 20 minute to 6 minutes to import 150,000 Tweets. If you’ve Tableau, or other software that can read OData, please try it out! If you’ve already got a connection set up, you need to go and get the […]
Where do tweets come from?
In our Twitter search tool, we provide the location of tweets via the latitude and longitude data Twitter offers. If you want to know about where the user was who created a particular tweet, it’s unfortunate then that most Twitter users (including me) don’t enable this feature. What you usually find are rare sightings of […]
What’s Twitter time zone data good for?
The Twitter friends tool has just been improved to retrieve the time zone of users. This is actually more useful than it first might sound. If you’ve looked at Twitter profiles before, you’ve probably noticed that users can, and sometimes do, enter anything they like as their location. Looking at @ScraperWiki‘s followers, we can see […]
World Cup Hack Day, London 10th June – a teaser!
With the England team just arrived in Miami for their final preparations for the World Cup, Mohammed Bin Hammam is back in the news for further accusations of corruption. This is interesting because we saw Hammam’s name on Friday as we were testing out the NewsReader technology in preparation for our Hack Day in London […]
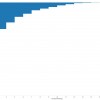
Getting all the hash tags, user mentions…
We’ve rolled out a change so you get more data when you use the Twitter search tool! We’ve changed four columns. They used to all just randomly return one thing. Now they return all the things, separated by a space. The columns are: hashtags now returns all of them with the hashes, e.g. #opendata #opendevelopment user_mention has […]

Book review: Learning SPARQL by Bob DuCharme
The NewsReader project on which we are working at ScraperWiki uses semantic web technology and natural language processing to derive meaning from the news. We are building a simple API to give access to the NewsReader datastore, whose native interface is SPARQL. SPARQL is a SQL-like query language used to access data stored in the […]
Internship – Scraperwiki
Hi, I am Patrick. I am currently in Year 10 at the British International School of Stavanger. As part of our curriculum, we are required to have one week of work experience. For my work experience, I worked at Scraperwiki from May 12 to 16 (2014). I found it a real privilege to be able […]
Two jobs at ScraperWiki to ponder over the bank holiday
It’s busy busy at ScraperWiki at the moment. We’re growing our award winning data hub (where people scrape Twitter). We’ve lots of interesting consultancy, for clients like the Cabinet Office (GDS), United Nations (OCHA), and Autotrader. So we’re hiring two people. 1) A Digital Marketer. This is an unusual opportunity to market a marketing data product! […]
Connecting QlikView to ScraperWiki with OData
This is a guest post by Nuno Faustino who shows how to connect QlikView to ScraperWiki using our new Odata connector. The first step is to collect some data using the ScraperWiki Platform, the demonstration here uses the our new US Stock Market data tool but could equally well have used the Twitter Follower or Twitter […]
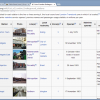
Hiding invisible text in Table Xtract
As part of the my London Underground visualisation project I wanted to get data out of a table on Wikipedia, you can see it below. It contains data on every London Underground station including things like the name of the station, the opening date, which zone it is in, how many passengers travel through it […]