Enterprise data analysis and visualization
The topic for today is a paper[1] by members of the Stanford Visualization Group on interviews with data analysts, entitled “Enterprise Data Analysis and Visualization: An Interview Study”. This is clearly relevant to us here at ScraperWiki, and thankfully their analysis fits in with the things we are trying to achieve.
The study is compiled from interviews with 35 data analysts across a range of business sectors including finance, health care, social networking, marketing and retail. The respondents are harvested via personal contacts and predominantly from Northern California; as such it is not a random sample, we should consider results to be qualitatively indicative rather than quantitatively accurate.
The study identifies three classes of analyst whom they refer to as Hackers, Scripters and Application Users. The Hacker role was defined as those chaining together different analysis tools to reach a final data analysis. Scripters, on the other hand, conducted most of their analysis in one package such as R or Matlab and were less likely to scrape raw data sources. Scripters tended to carry out more sophisticated analysis than Hackers, with analysis and visualisation all in the single software package. Finally, Application Users worked largely in Excel with data supplied to them by IT departments. I suspect a wider survey would show a predominance of Application Users and a relatively smaller relative population of Hackers.
The authors divide the process of data analysis into 5 broad phases Discovery – Wrangle – Profile – Model – Report. These phases are generally self explanatory – wrangling is the process of parsing data into a format suitable for further analysis and profiling is the process of checking the data quality and establishing fully the nature of the data.
This is all summarised in the figure below, each column represents an individual so we can see in this sample that Hackers predominate.
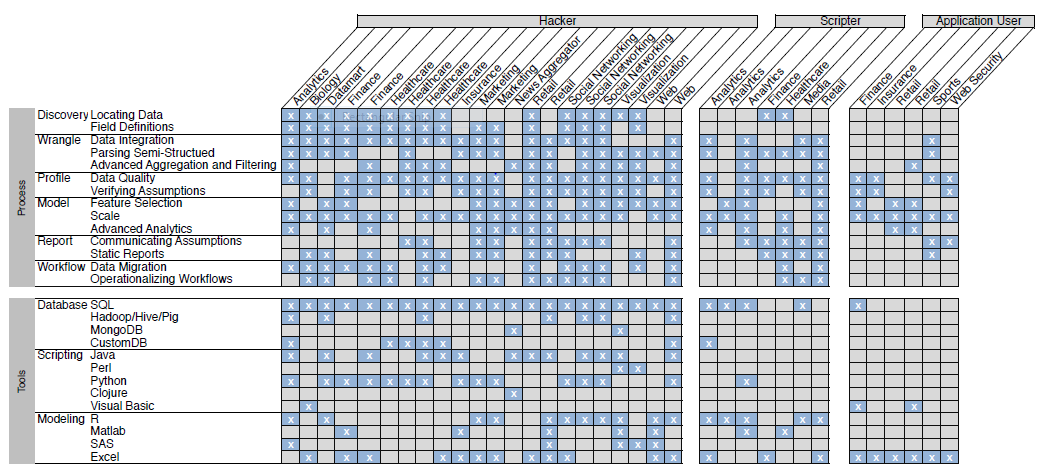
At the bottom of the table are identified the tools used, divided into database, scripting and modeling types. Looking across the tools in use SQL is key in databases, Java and Python in scripting, R and Excel in modeling. It’s interesting to note here that even the Hackers make quite heavy use of Excel.
The paper goes on to discuss the organizational and collaborative structures in which data analysts work, frequently an IT department is responsible for internal data sources and the productionising of analysis workflows.
Its interesting to highlight the pain points identified by interviewees and interviewers:
- scripts and intermediate data not shared;
- discovery and wrangling are time consuming and tedious processes;
- workflows not reusable;
- ingesting semi-structured data such as log files is challenging.
Why does this happen? Typically the wrangling scraping phase of the operation is ad hoc, the scripts used are short, practioners don’t see this as their core expertise and they’ll typically draw from a limited number of data sources meaning there is little scope to build generic tools. Revision control tends not to be used, even for the scripting tools where it is relatively straightforward perhaps because practioners have not been introduced to revision control or simply see the code they write as too insignificant to bother with revision control.
ScraperWiki has its roots in data journalism, open source software and community action but the tools we build are broadly applicable, as one of the respondents to the survey said:
“An analyst at a large hedge fund noted their organization’s ability to make use of publicly available but poorly-structured data was their primary advantage over competitors.”
References