So web scraping is easy?
Journalists, academics and budding open data hackers often praise ScraperWiki for making web scraping easy. And while it’s true our platform and powerful APIs let you get more done, more easily, the statement still creates some head-scratching at ScraperWiki HQ.
That’s because, as far as we can tell, scraping is hard, no matter what platform you’re using.
For example, let’s pretend you’re scraping a fairly ordinary web page that has some data as a table. Barely a sentence in and we already need to know about HTML and URLs. We need to access this page programmatically, so we need to pick a language to write a scraper in. Say Python. How do we select the elements we need from the table? A CSS selector. The header is blue, so how do we detect the colour of an element? RGB hex-triples…
A little bit more thinking like this leads to something like this diagram:
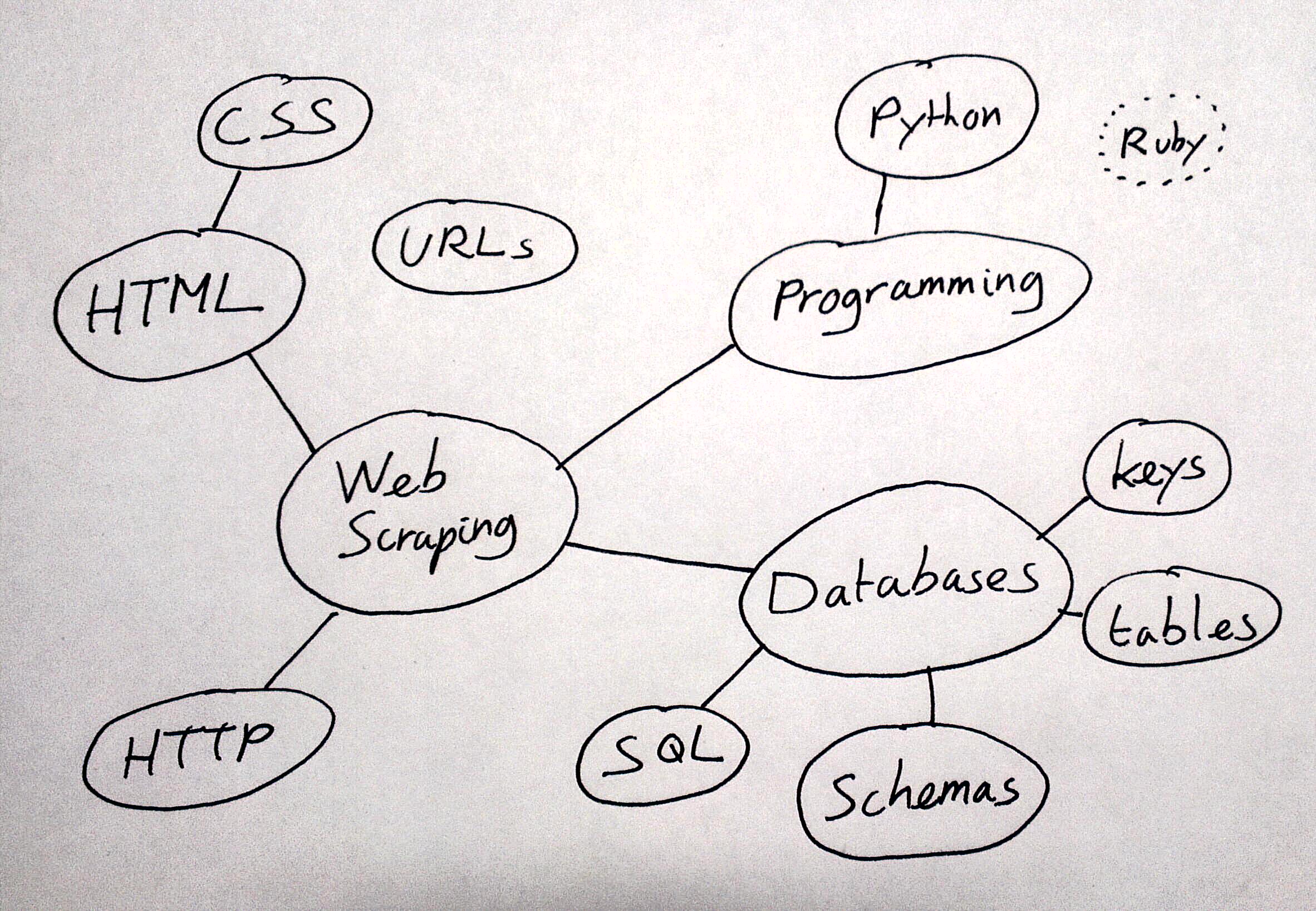
Web Scraping Concepts
If you need to know web scraping, you need to know all that. Admittedly, you don’t need to be an expert (not for most scraping tasks), but you do need to know at least a little bit about lots of things before you can even begin to get something useful out of a web page.
And that’s just a web page. What if you’re scraping PDFs? There’s a whole extra little “tree of knowledge” to do with PDFs. And one for KML. And another one for SVG. And another one for Excel and another for CSVs. And another one for those hipster fixie formats that the climate science community like to use. And then, once you need to visualise your findings, you’re into CSS (styles this time, rather than just selectors), Javascript libraries and plugins, and maybe even (La)TeX.
That’s why we’re changing ScraperWiki. Knowing all this stuff gives you immense power and flexibility, but it’s a tall ask when you just want to quickly grab and analyse some data off the web. By using pre-built data tools on the new ScraperWiki, you get to perform the most common tasks, quickly and easily, without having to take evening classes in Computer Science. And then, once you hit the tool’s limitations (because eventually you always will) you can fork and tweak the code, without having to start again from scratch. And in the process, maybe you’ll even learn something about HTML, CSS, XPath, JSON, Javascript, CSVs, Excel, PDFs, KML, SVGs…
This seems like a great way to overcome Dietzler’s Law http://nealford.com/memeagora/2013/01/22/why_everyone_eventually_hates_maven.html
Thanks for that m, really interesting post!