Glue Logic and Flowable Data
Guest post by Tony Hirst

As well as being a great tool for scraping and aggregating content from third party sites, Scraperwiki can be used as a transformational “glue logic” tool: joining together applications that utilise otherwise incompatible data formats. Typically, we might think of using a scraper to pull data into one or more Scraperwiki database tables and then a view to develop an application style view over the data. Alternatively, we might just download the data so that we can analyse it elsewhere. There is another way of using Scraperwiki, though, and that is to give life to data as flowable web data.
Ever since I first read The UN peacekeeping mission contributions mostly baked just over a year ago, I’ve had many guilty moments using Scraperwiki, grabbing down data and then… nothing. In that post, Julian Todd opened up with a salvo against those of us that create a scraper that sort of works and then think: “Job done.”
Many of the most promising webscraping projects are abandoned when they are half done. The author often doesn’t know it. “What do you want? I’ve fully scraped the data,” they say.
But it’s not good enough. You have to show what you can do with the data. This is always very hard work. There are no two ways about it.
So whilst I have created more than my fair share of half-abandoned scraper projects, I always feel a little bit guilty about not developing an actual application around a scraped dataset. My excuse? I don’t really know how to create applications at all, let alone applications that anyone might use… But on reflection, Julian’s quote above doesn’t necessarily imply that you always need to build an application around a data set, it just suggests that you should “show what you can do with the data”. Which to my mind includes showing how you can free up the data so that it can naturally flow into other tools and applications.
One great way of showing what you can do with the data is to give some example queries over your Scraperwiki database using the Scraperwiki API. A lot of “very hard work” may be involved (at least for a novice) in framing a query that allows you to ask a particular sort of question over a database, but once written, such queries can often be parametrised, allowing the user to just change one or two search terms, or modify a specified search range. Working queries also provide a good starting point for developing new queries by means of refining old ones. The Scraperwiki API offers a variety of output formats—CSV, JSON, HTML data tables—which means that your query might actually provide the basis for a minimum viable application, providing URL accessible custom data views via and HTML table, for example.
Though playing with a wide variety of visualisation tools and toolkits, I have learned a couple of very trivial sounding but nonetheless important lessons:
- different tools work out-of-the-box with different data import formats
- a wide variety of data visualisation toolkits can generate visualisations for you out-of-the-box if the data has the right shape (for example, the columns and rows are defined in a particular way or using a particular arrangement).
As an example of the first kind, if you have data in the Google Visualisation API JSON data format, you can plug it directly into a sortable table component, or more complex interactive dashboard. For example, in Exporting and Displaying Scraperwiki Datasets Using the Google Visualisation API I describe how data in the appropriate JSON format can be plugged into an HTML view that generates a sortable table with just the following lines of code:
[sourcecode language=”javascript”]
//jsonData contains data in the appropriate format
var json_table = new google.visualization.Table(document.getElementById(‘table_div_json’))
var json_data = new google.visualization.DataTable(jsonData, 0.6);
json_table.draw(json_data, {
showRowNumber: true
});
[/sourcecode]
An example of the second kind might be getting data formatted correctly for a motion chart.
To make life easier, some of the programming libraries that are preinstalled on Scraperwiki can generate data in the correct format from you. In the case of the above example, I used the gviz_api Python library to transform data obtained using a Scraperwiki API query into the format expected by the sortable table.
Also in that example, I used a single Scraperwiki Python view to pull down the data, transform it, and then paste it into a templated HTML page.
Another approach is to create a view that generates a data feed—accessible via its own URL—and then consume that feed either in another view—or in another application or webpage outside the Scraperwiki context altogether. This is the approach I took when trying to map co-director networks using data sourced from OpenCorporates (described in Co-Director Network Data Files in GEXF and JSON from OpenCorporates Data via Scraperwiki and networkx).
Here’s the route I took—one thing to reflect on is not necessarily the actual tools used, more the architecture of the approach: 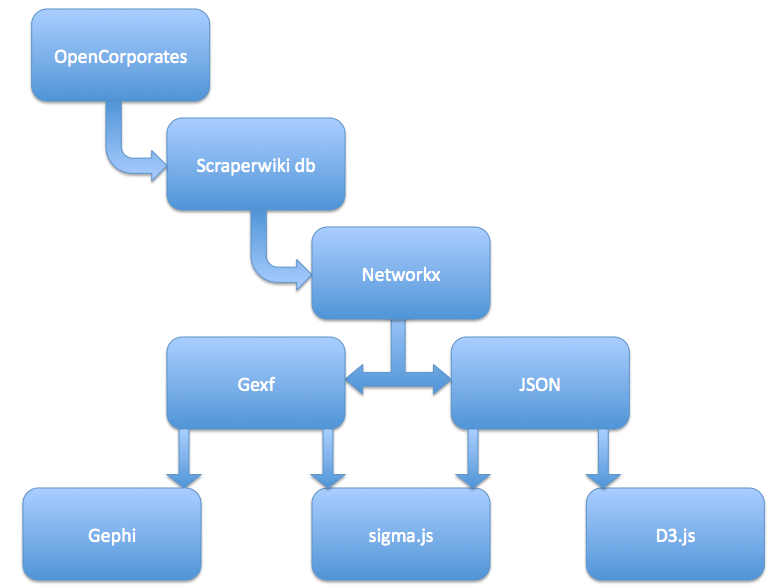 In this case, I used Scraperwiki to run a bootstrapped search over OpenCorporates, first finding the directors of a particular company, then searching for other directors with the same name, then pulling down company details corresponding to those director records, and so on. A single Scraperwiki table could then be used to build up list of (director, company) pairs showing how companies were connected based on co-director links. This sort of data is naturally described using a graph (graph theory style, rather than line chart!;-), the sort of object that is itself naturally visualised using a network style layout. But they’re hard to generate, right?
In this case, I used Scraperwiki to run a bootstrapped search over OpenCorporates, first finding the directors of a particular company, then searching for other directors with the same name, then pulling down company details corresponding to those director records, and so on. A single Scraperwiki table could then be used to build up list of (director, company) pairs showing how companies were connected based on co-director links. This sort of data is naturally described using a graph (graph theory style, rather than line chart!;-), the sort of object that is itself naturally visualised using a network style layout. But they’re hard to generate, right?
Wrong… Javascript libraries such as d3.js and sigma.js both provide routes to browser based network visualised data if you use the right sort of JSON or XML format. And it just so happens that another of the Python libraries available on Scraperwiki—networkx—is capable of generating those data formats from a graph that is straightforwardly constructed from the (director, company) paired data.
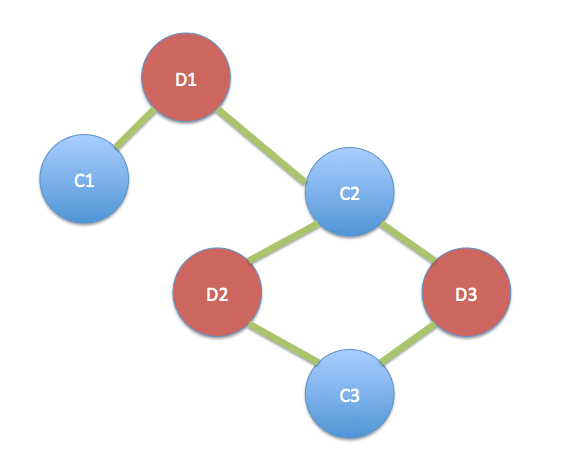
As a graph processing library, networkx can also be used to analyse the corporate data using network methods—for example, reducing the director1-company-director2 relations to director1-director2 relations (showing directors related by virtue of being co-directors of one or more of the same companies), or performing a complementary mapping for company1-director-company2 style relations.
As Scraperwiki views can be passed, and hence act on, URL variables, it’s possible to parametrise the “graph view” to return data in different formats (JSON or XML) as well as in different views (full graph, director-director mapping etc). Which I hope shows one or two ways of using the data, along with making it easier for someone else with an eye for design to pull that data into an actual end-user application.
Tony Hirst is an academic in the Dept of Communication and Systems at The Open University and member of the Open Knowledge Foundation Network. He blogs regularly at ouseful.info and on OpenLearn. Tony’s profile pic from ouseful.info was taken by John Naughton.
Trackbacks/Pingbacks
[…] Read the whole thing here: Glue Logic and Flowable Data. […]