WordPress Titles: scraping with search url
 I’ve blogged for a few years now, and I’ve used several tools along the way. zachbeauvais.com began as a Drupal site, until I worked out that it’s a bit overkill, and switched to WordPress. Recently, I’ve been toying with the idea of using a static site generator (a lá Jekyll or Hyde), or even pulling together a kind of ebook of ramblings. I also want to be able to arrange the posts based on the keywords they contain, regardless of how they’re categorised or tagged.
I’ve blogged for a few years now, and I’ve used several tools along the way. zachbeauvais.com began as a Drupal site, until I worked out that it’s a bit overkill, and switched to WordPress. Recently, I’ve been toying with the idea of using a static site generator (a lá Jekyll or Hyde), or even pulling together a kind of ebook of ramblings. I also want to be able to arrange the posts based on the keywords they contain, regardless of how they’re categorised or tagged.
Whatever I wanted to do, I ended up with a single point of messiness: individual blog posts, and how they’re formatted. When I started, I seem to remember using Drupal’s truly awful WYSIWYG editor, and tweaking the HTML soup it produced. Then, when I moved over to WordPress, it pulled all the posts and metadata through via RSS, and I tweaked with the visual and text tools which are baked into the engine.

markdown
A couple years ago, I started to write in Markdown, and completely apart from the blog (thanks to full-screen writing and loud music). This gives me a local .md file, and I copy/paste into WordPress using a plugin to get rid of the visual editor entirely.
So, I wrote a scraper to return a list of blog posts containing a specific term. What I hope is that this very simple scraper is useful to others—WordPress is pretty common, after all—and to get some ideas for improving it, and handle post content. If you haven’t used ScraperWiki before, you might not know that you can see the raw scraper by clicking “view source” from the scraper’s overview page (or going here if you’re lazy).
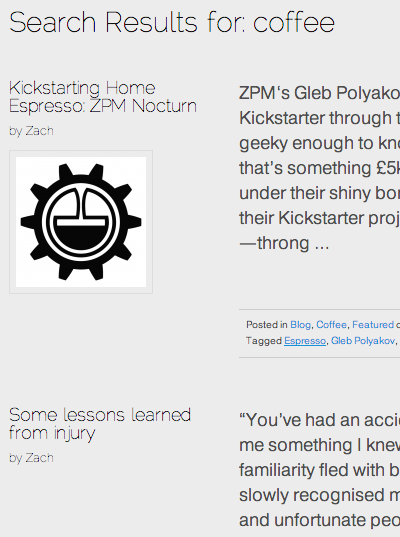
This scraper is based on WordPress’ built-in search, which can be used by passing the search terms to a url, then scraping the resulting page:
http://zachbeauvais.com/?s=search_term&submit=Search
The scraper uses three Python libraries:
There are two variables which can be changed to search for other terms, or using a different WordPress site:
[sourcecode language=”python”]
term = “coffee”
site = “http://www.zachbeauvais.com”
[/sourcecode]
The rest of the script is really simple: it creates a dictionary called “payload” containing the letter “s”, the keyword, and the instruction to search. The “s” is in there to make up the search url: /?s=coffee …
Requests then GETs the site, passing payload as url parameters, and I use Request’s .text function to render the page in html, which I then pass through lxml to the new variable “root”.
[sourcecode language=”python”]
payload = {‘s’: str(term), ‘submit’: ‘Search’}
r = requests.get(site, params=payload) # This’ll be the results page
html = r.text
root = lxml.html.fromstring(html) # parsing the HTML into the var root
[/sourcecode]
Now, my WordPress theme renders the titles of the retrieved posts in <h1> tags with the CSS class “entry-title”, so I loop through the html text, pulling out the links and text from all the resulting h1.entry-title items. This part of the script would need tweaking, depending on the CSS class and h-tag your theme uses.
[sourcecode language=”python”]
for i in root.cssselect(“h1.entry-title a”):
link = i.cssselect(“a”)
text = i.text_content()
data = {
‘uri’: link[0].attrib[‘href’],
‘post-title’: str(text),
‘search-term’: str(term)
}
if i is not None:
print link
print text
print data
scraperwiki.sqlite.save(unique_keys=[‘uri’], data=data)
else:
print “No results.”
[/sourcecode]
These return into an sqlite database via the ScraperWiki library, and I have a resulting database with the title and link to every blog post containing the keyword.
So, this could, in theory, run on any WordPress instance which uses the same search pattern URL—just change the site variable to match.
Also, you can run this again and again, changing the term to any new keyword. These will be stored in the DB with the keyword in its own column to identify what you were looking for.
See? Pretty simple scraping.
So, what I’d like next is to have a local copy of every post in a single format.
Has anyone got any ideas how I could improve this? And, has anyone used WordPress’ JSON API? It might be a logical next step to call the API to get the posts directly from the MySQL DB… but that would be a new blog post!
Hi Zach – That’s very smart. I’ve just been playing with this and using it for WooCommerce product scraping. WooCommerce search results can be found using:
/shop/?s=search-query&post_type=product
Could be useful. Cheers