Tools of the trade

With the experience of a whole week of ScraperWiki, I am starting to appreciate the core tools of the professional Data Scientist.
In the past I’ve written scrapers in Matlab, C# and Python. However, the house language for scraping at ScraperWiki is Python. It’s a good choice: a mature but modern language with a wide range of useful, easy to install libraries. As an interpreted language, it is easy to use in a very fast development cycle.
There are a number of libraries which are core to the scraping process:
Requests is an HTTP library for reading web pages. It has a rather cleaner syntax than the standard urllib2 and has useful plugins such as requests_cache which gives you dead simple web page caching. Add import statement and one further line, and you’re good to go—handy when you are building your scraper and repeatedly testing on the same few webpages.
lxml is an XML and HTML processing library. It’s a small challenge to install on Windows, your best bet is to download the pre-built binaries from here. lxml lets you select elements from a document or web page using CSS selectors, or the XPath query language. This is absolutely fundamental to web scraping and indeed PDF scraping since we typically convert PDF to XML (using pdftoxml). You can think of the structure of a webpage as being like a tree: the individual leaves are the elements which you see on the screen. XPath is a tool to select either leaves of the tree based on their properties or sets of leaves attached to certain branches. It is a tremendously powerful tool but has a substantial learning curve.
Building XPath queries is something of a dark art. We use the XPath helper Chrome plugin which builds queries based on webpage selection. These may not be the most elegant queries, but they are a good basis for further work. Alongside this, the developer console is almost permanently open so the underlying HTML structure of a webpage can be viewed.
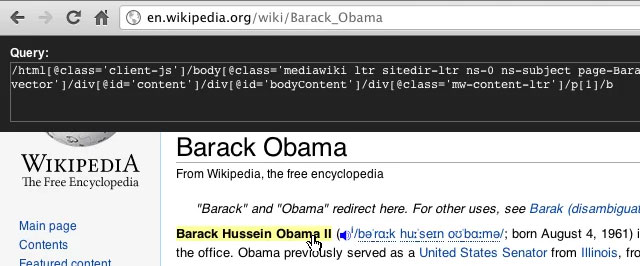
Scrapy is a scraping framework library which handles the messy business of fetching webpages, marshalling stuff, and doing output-related things; leaving us to do the core job of identifying what we want to scrape, and the XPath queries to achieve that aim. It depends on lxml, so Windows users should install from binaries as described above, and it also requires PyOpenSSL which can be installed, for Windows users, from here.
Dragon isn’t a conventional Python library, but as an experienced scraper he fulfills a critical role in helping newcomers learning the tools of the trade!
That covers the highlights of my first week of professional scraping. Bubbling under were virtual environments in Python and building a tool chain for Windows which enables smooth inter-operation with my Linux and Mac based colleagues working on the ScraperWiki Platform. So maybe more news on that next week.
I’ve just started using Python, and I have to say, I’m *super* stoked on the Natural Language Toolkit (NLTK). I haven’t seen anything as sophisticated for text processing in any other language, it’s really cool!