pdftables – a Python library for getting tables out of PDF files
Try our web interface and API over at PDFTables.com!
One of the top searches bringing people to the ScraperWiki blog is “how do I scrape PDFs?” The answer typically being “with difficulty”, but things are getting better all the time.
PDF is a page description format, it has no knowledge of the logical structure of a document such as where titles are, or paragraphs, or whether it’s two column format or one column. It just knows where characters are on the page. The plot below shows how characters are laid out for a large table in a PDF file.
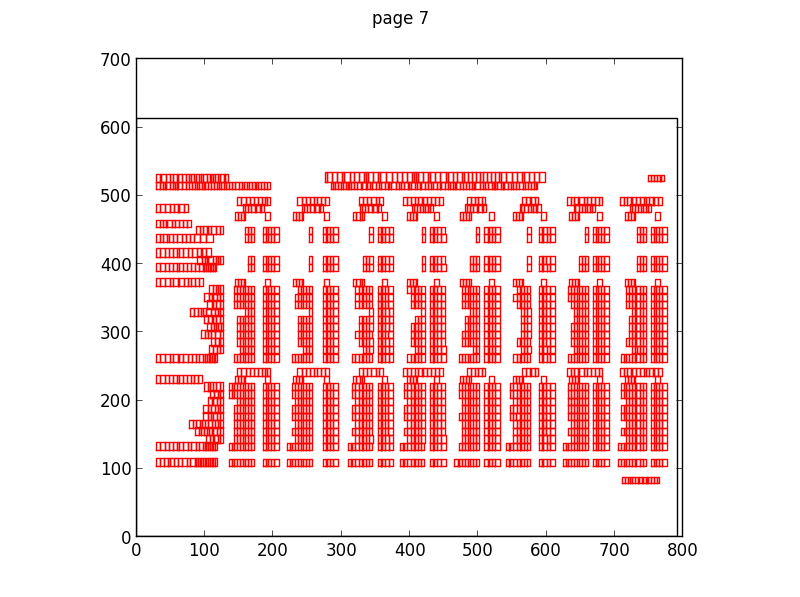
This makes extracting structured data from PDF a little challenging.
Don’t get me wrong, PDF is a useful format in the right place, if someone sends me a CV – I expect to get it in PDF because it’s a read only format. Send it in Microsoft Word format and the implication is that I can edit it – which makes no sense.
I’ve been parsing PDF files for a few years now, to start with using simple online PDF to text converters, then with pdftohtml which gave me better location data for text and now using the Python pdfminer library which extracts non-text elements and as well as bonding words into sentences and coherent blocks. This classification is shown in the plot below, the blue boxes show where pdfminer has joined characters together to make text boxes (which may be words or sentences). The red boxes show lines and rectangles (i.e. non-text elements).
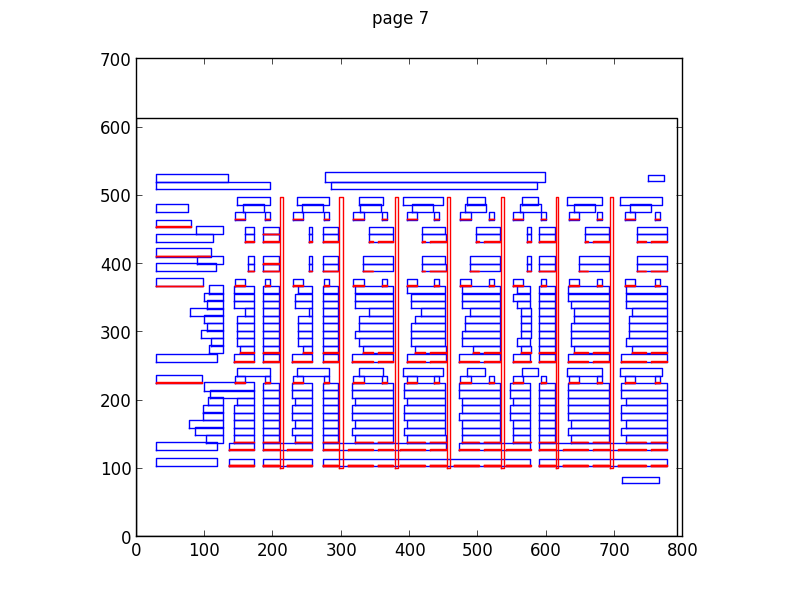
More widely at ScraperWiki we’ve been processing PDF since our inception with the tools I’ve described above and also the commercial, Abbyy software.
As well as processing text documents such as parliamentary proceedings, we’re also interested in tables of numbers. This is where the pdftables library comes in, we’re working towards making scrapers which are indifferent to the format in which a table is stored, receiving them via the OKFN messytables library which takes adapters to different file types. We’ve already added support to messytables for HTML, now its time for PDF support using our new, version-much-less-than-one pdftables library.
Amongst the alternatives to our own efforts are Mozilla’s Tabula, written in Ruby and requiring the user to draw around the target table, and Abbyy’s software which is commercial rather than open source.
pdftables can take a file handle and tell you which pages have tables on them, it can extract the contents of a specified page as a single table and by extension it can return all of the tables of a document (at the rate of one per page). It’s possible, for simple tables to do this with no parameters but for more difficult layouts it currently takes hints in the form of words found on the top and bottom rows of the table you are looking for. The tables are returned as a list of list of lists of strings, along with a diagnostic object which you can use to make plots. If you’re using the messytables library you just get back a tableset object.
It turns out the defining characteristic of a data scientist is that I plot things at the drop of a hat, I want to see the data I’m handling. And so it is with the development of the pdftables algorithms. The method used is inspired by image analysis algorithms, similar to the Hough transforms used in Tabula. A Hough transform will find arbitrarily oriented lines in an image but our problem is a little simpler – we’re interested in vertical and horizontal rows.
To find these vertical rows and columns we project the bounding boxes of the text on a page onto the horizontal axis ( to find the columns) and the vertical axis to find the rows. By projection we mean counting up the number of text elements along a given horizontal or vertical line. The row and column boundaries are marked by low values, gullies, in the plot of the projection. The rows and columns of the table form high mountains, you can see this clearly in the plot below. Here we are looking at the PDF page at the level of individual characters, the plots at the top and left show the projections. The black dots show where pdftables has placed the row and column boundaries.
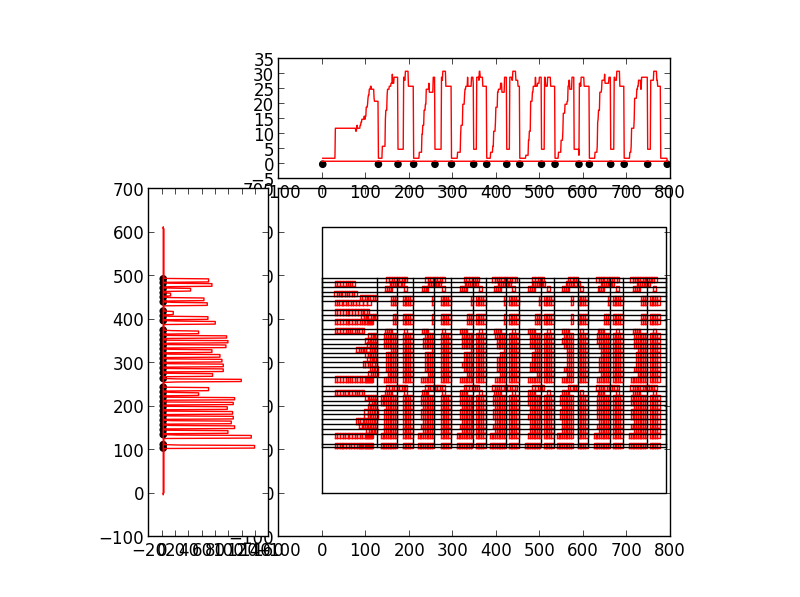
pdftables is currently useful for supervised use but not so good if you want to just throw PDF files at it. You can find pdftables on Github and you can see the functionality we are still working on in the issue tracker. Top priorities are finding more than one table on a page and identifying multi-column text layouts to help with this process.
You’re invited to have a play and tell us what you think – ian@scraperwiki.com
Try our web interface and API over at PDFTables.com!
Does the switch the pdfminer bring additional functionality or was it just in the name of Python purity? Are Tabula and Abby the only two other PDF table extraction packages that you’ve evaluated? Have you run your algorithm against the PDF table extraction ground truth data set from ICDAR 2013? http://www.tamirhassan.com/dataset.html
pdfminer brings additional functionality over pdftohtml, hence the switch – the fact it is Python based is convenient but not essential.
We’ve used Abby in the past, and if we go down the commercial application route we’d probably stick with them. I’ve seen various open source alternatives but none seemed to be considered the obvious go-to solution. Anyway, I fancied having a play with the problem myself 😉
Thanks for pointing out the ground truth data set – hadn’t seen it before and it looks very handy.