Introducing the Search for Tweets tool
Hey – my name is Ed Cawthorne and I have recently started with ScraperWiki as the resident product manager.
My first task is to let you know about the “Search for Tweets” tool on the new ScraperWiki platform.
To understand how the Twitter tool came about, it is useful to understand some of the background.
On ScraperWiki Classic, we found that a large number of people were forking a standard Twitter scraper and simply changing the search term in the code. The search terms were incredibly varied but customers were certainly getting value from a relatively easy way of accessing Twitter data.

This behaviour influenced the tool strategy as a way of making data available to those of us that don’t have the time, inclination or skill to build our own scrapers. The “Search for Tweets” tool couldn’t get any easier: simply type your search terms and you will be presented with a table view of the last 7 or so days of tweets with that content.
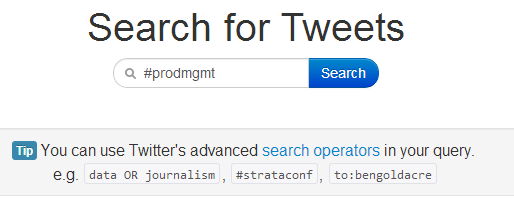
Once you have used the Search for Tweets tool to to find your data you can use other tools such as the “Summarise this Data” or “Download as a Spreadsheet” tools to clean up, analyse and visualise the data. Again, these tools don’t require any coding.
One thing to note is that we can only provide access to about 1 week’s worth of data due to some limitations of the Twitter API but that should still provide many of you with some great data to analyse. And as time passes on, the tool continues gathering search results, so the longer you leave it, the more data you collect.
We have written a great little help article that shows how to use the tool. Why not try it out?
As a product manager, I am keen to hear any feedback you might have on this or any other aspects of ScraperWiki – you can contact me at ed@scraperwiki.com.
Trackbacks/Pingbacks
[…] -Introducing the Search for Tweets tool – ScraperWiki blog […]
[…] is a job for the ScraperWiki Search for tweets tool! Getting this going is simply a matter of typing in a search term and clicking a couple of […]