Scraping for kittens
Like most people who possess a pulse and an internet connection, I think kittens are absurdly cute and quite possibly the vehicle in which humanity will usher in an era of world peace. I mean, who doesn’t? They’re adorable.
I was genuinely curious as to what country has the cutest kittens. I therefore decided to write a tool to find out! I used our new ScraperWiki platform, Python and the Flickr API, and I decided to search for all the photos that contain geotags and a reference to the word ‘kitten’. All the data that I’d retrieve would then be plotted on a map.
My Development Environment And The Flickr API
Flickr has a really powerful, mature, well documented API. It comes with a reasonably generous limit and if you ever get stuck using it, you’ll discover that there’s a great deal of support out there.
Gaining access to the API is pretty trivial too. Just sign into Flickr, click here and follow the instructions. Once you’ve received your API key and secret, put it in a safe place. We’re going to need it later.
First, however, you will need to log into Scraperwiki and create yourself a new dataset. Once you’ve done that, you will be able to SSH in and set up your development environment. Whilst you may have your own preferences, I recommend using our Data Services Scraper Template.
Here’s what Paul Furley – its author – has to say about it.
“The Scraper Template allows you to set up a box in a minimum amount of time and allows you to be consistent across all of your boxes. It provides all the common stuff that people use in scrapers, such as unicode support, scheduling and autodocs, as well as helping you manage your virtual environment with virtualenv. It handles the boring stuff for you.”
How I Scraped Flickr
There are a couple of prerequisites that you’ll need to satisfy for your tool to work. Firstly, if you’re using a virtualenv, you should ensure that you have the ‘scraperwiki’ library installed.
It’s also essential that you install ‘flickrapi’. This is the awesome little library that will handle all the heavy lifting, when it comes to scraping Flickr. Both of these libraries are easily found in ‘pip’ and can be installed by running the following command:
$ pip install flickrapi scraperwiki
If you’ve used the Scraper Template, you’ll find a file called ‘main.py’ in ‘~/tool/’. Delete the contents of this file. If it doesn’t already exist, create it. In your favorite text editor, open it up and add the following lines:
Here, we’re importing the modules and classes we need, assigning our API key to a variable and instantiating the FlickrAPI class.
Later on, we’re going to write a function that contains the bulk of our scraper. We want this function to be executed whenever our program is run. The above two lines do exactly that.
In our ‘main’ function, we call call ‘flickr.walk(). This handy little method gives you access to Flickr’s search engine. We’re passing in two parameters. The first searches for photos that contain the keyword ‘kittens’. The second gives us access to the geotags associated with each photo.
We then iterate through our results. Because we’re looking for photos that have geotags, if any of our results have a latitude value of ‘0’, we want to move on to the next item in our results. Otherwise we assign the the title, the unique flickr ID number associated with the photo, its URL and its coordinates to variables and we then call ‘submit_to_scraperwiki’. This is a function we’ll define that allows us to insert our results into a SQLite file that will be presented in a ScraperWiki view.
Submit_to_scraperwiki is a handy little function that that takes the dictionary of values that we’re going to shove into our database. This contains all the results that we pull from Flickr and then shoves them into a table called ‘kittens’.
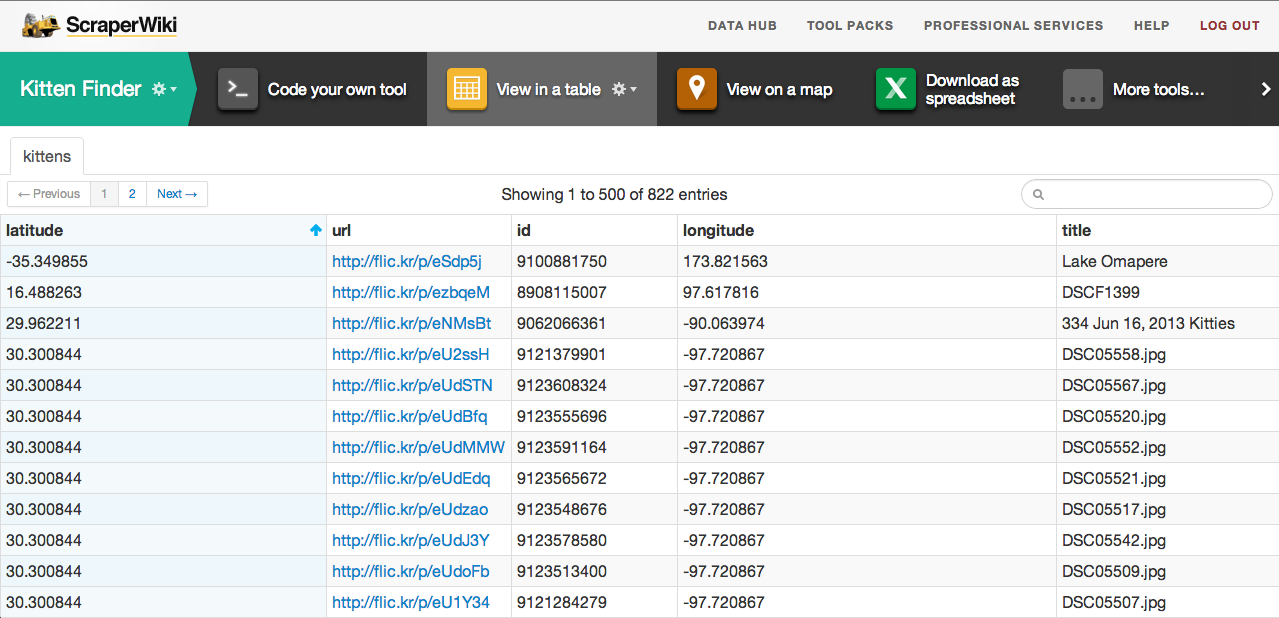
So, we’ve located all our kitties. What now? Let’s plot them on a map!
In your browser, navigate to your dataset. Inside it, click on ‘More tools’. You’ll see a list of all the possible tools you can use in order to better visualize your data.
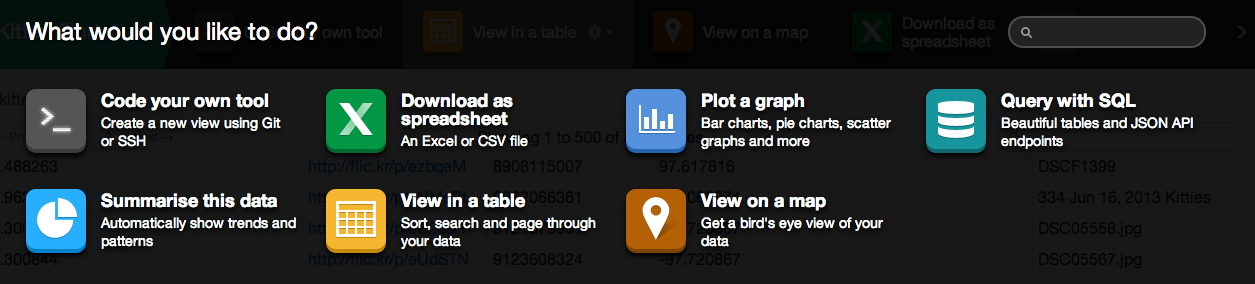
As you can see, there’s a lot of tools that you can use. We just want to select ‘View on a map’. This automatically looks at our data and places it on a map. This works because the tool recognises and extracts the latitude and longitude columns that are stored in the database.
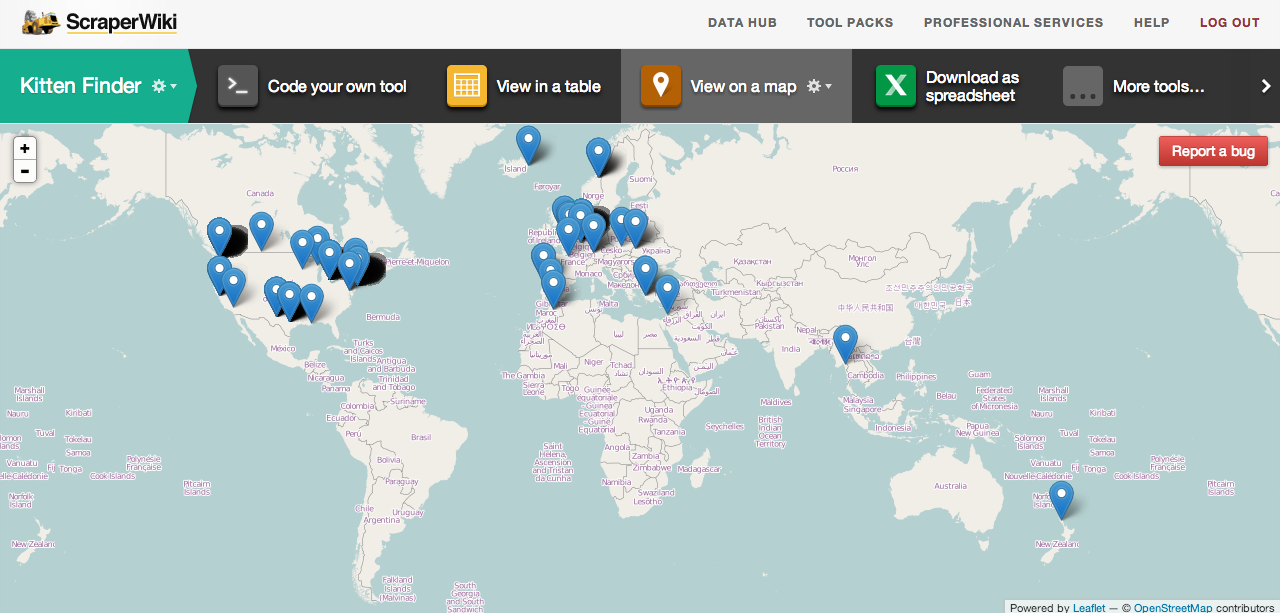
Once you’ve added this tool to your datahub, you can then see each result that you have stored on a map. Here’s what it looks like!
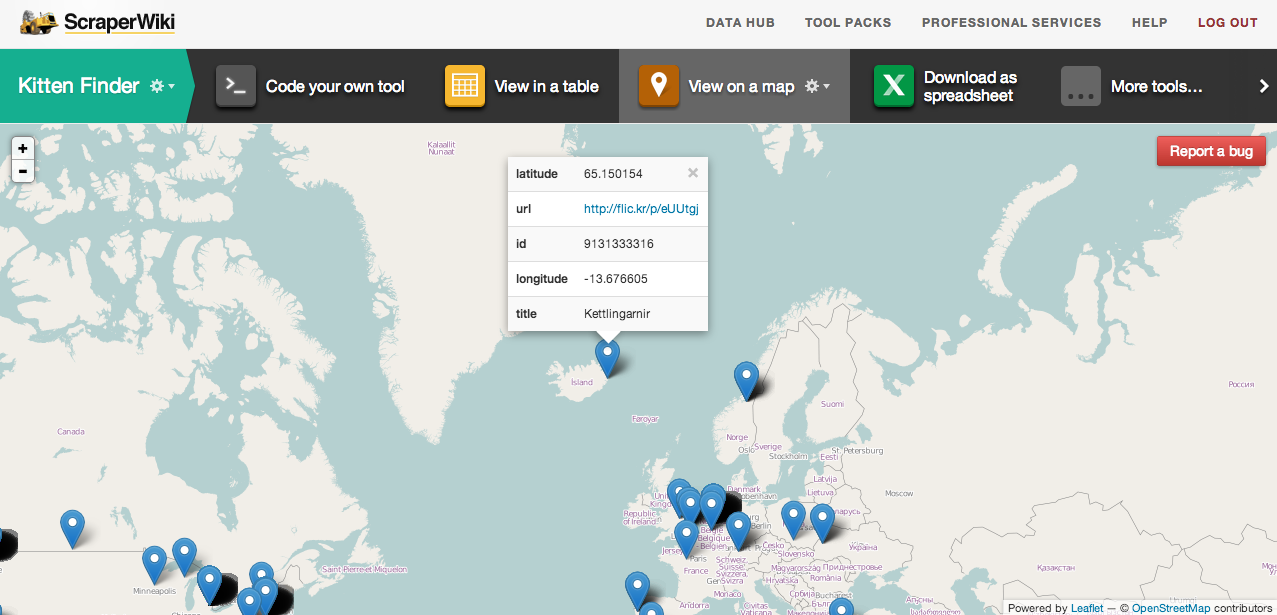
When you click on a ‘pin’, you’ll see all the information relating to the photo of a kitty it represents.
My First Tool
This was the first tool that I’ve made on the new platform. I was a bit apprehensive, as I had previously only used ScraperWiki Classic and I was very much used to writing my scrapers in the browser.
However, I soon discovered that the latest iteration of the Scraperwiki platform is nothing short of a joy to use. It’s something that was obviously designed from the ground up with the user’s experience in mind.
Things just worked. Vim has a bunch of useful plugins installed, including syntax highlighting. There’s a huge choice of programming languages. The ‘View on a map’ tool just worked. It was snappy and responsive. It’s also really, really fun.
You can try out my tool too! We have decided to adapt it to a general purpose Flickr search tool, and it is available to download right now! Next time you create a new dataset, have a look at ‘Flickr Geo Search’ and tell me what you think!
So, what’s your next tool going to be?
Scraperwiki SSH thing throws an error “ReferenceError: event is not defined” in Firefox. No problem on Chrome