The four kinds of data PDF
At ScraperWiki, we talk to lots of customers who need to convert PDFs to Excel.
Why are they doing it?
The industries are diverse – banking, insurance, retail, logistics, political campaigning, energy…
What separates them in data terms though, is each has one of four different kinds of workflow.
A. Large tables
These are PDFs which are printed from databases. One PDF may have as many as half a million values in it.
For example, this PDF of Ugandan election results has a single enormous table spread over 1168 pages. Every page has the same 22 columns.
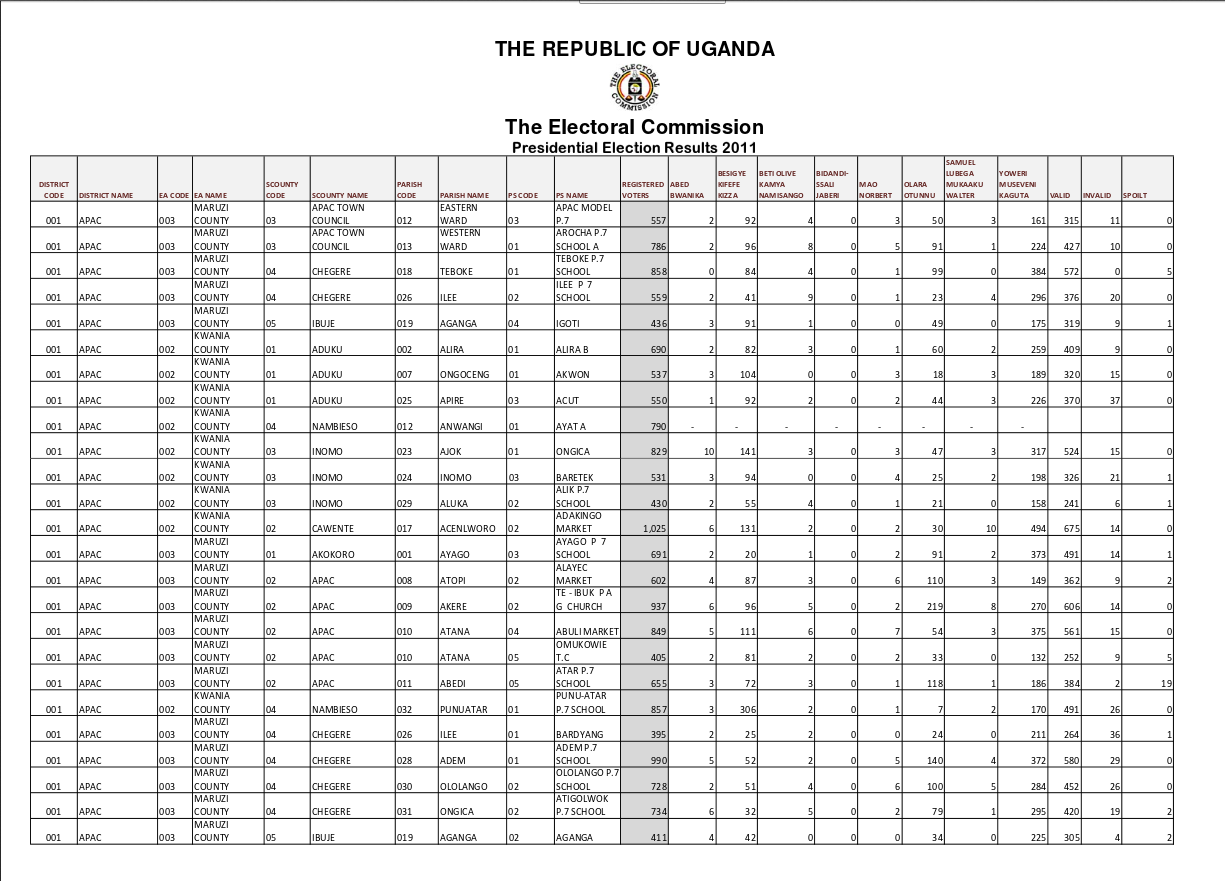
The key thing here is that the data is uniform, and there’s lots of it in the same form.
Once extracted to Excel by PDF Tables, the data can be easily loaded into a database, BI software or a stats package and queried.
B. Pivotted tables
A typical spreadsheet isn’t a pure table of numbers. Often there are headings and subheadings and data spread between tabs. There are subtotals and totals. If you’ve ever used pivot tables, these spreadsheets are a bit like one.
For example, look at this citrus production PDF from the US Department of Agriculture.
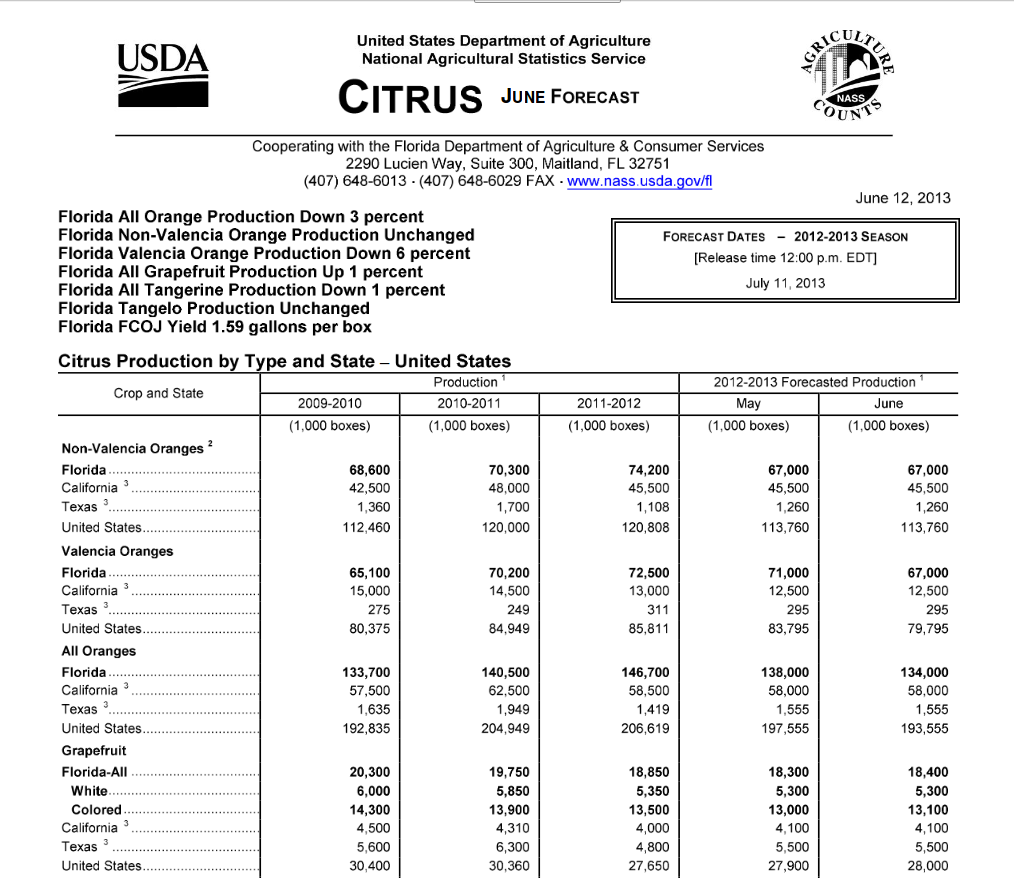
Even when you’ve got its content out into a spreadsheet, it still isn’t data. The varieties of orange are interleaved with the states as subheadings. Annual production is mixed up in the same table as monthly forecasts.
To a human, such digital paper is easy to understand. To an SQL database, it first needs “unpivotting”. That’s the kind of tricky work ScraperWiki’s DataBaker product is designed for.
C. Transactions
Here, each PDF represents one transaction. It might be an invoice, a derivative trade, a purchase order or a property transfer.
Most of the important data will only appear once in each PDF, and there will be lots of PDFs. For example, each PDF may have one sender, one recipient, one transaction number and one total cost. There might be multiple purchase line items, forming a subtable.
Have a look at this invoice – it’s from Wikipedia, so I can share it. Most transaction PDFs are very private!
{kind=link}

The buyer, the seller, their addresses, the invoice number, the ship data, the total… In data terms those are all in one row of an invoice table. There’s also a subtable, with the individual items being invoiced for.
Often organisations end up with legacy systems, where EDI never got implemented, and receive transactions as PDFs, usually over email or SFTP. PDF Tables helps unpick that, and automate the flow of data again.
D. Reports
The final kind of PDF mixes text and images with tables. Company reports are a typical example.
For example, this is page 221 of General Electric’s 2014 Annual Report.
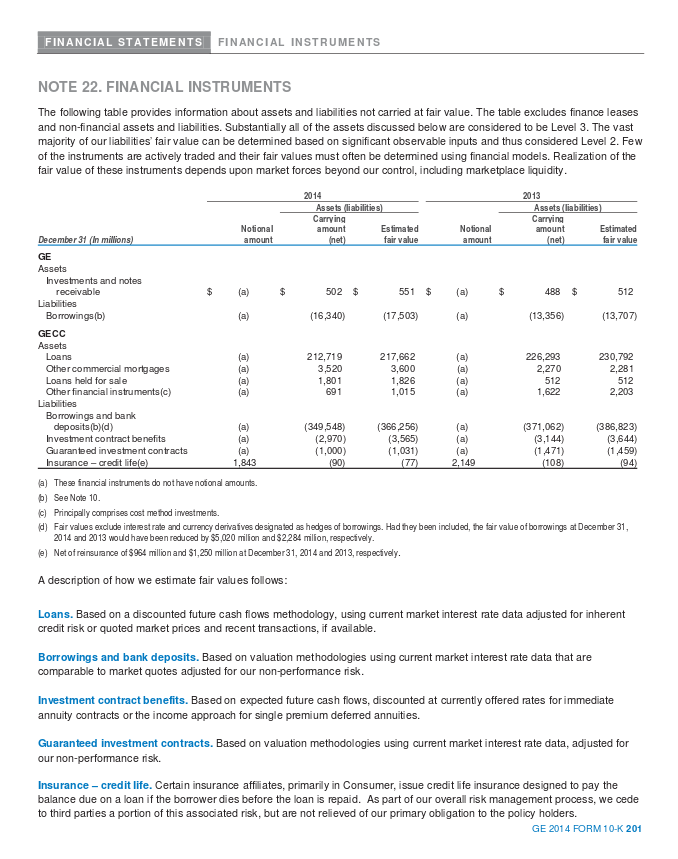
Usually, a few individual tables are required. Copy and paste would be ideal. Meanwhile, you can convert them online with PDF Tables, which has an option to download in an Excel file with a tab for each page (“multiple sheets”).
Conclusion
These four kinds of PDF are different in both:
- The software used to make them – A) databases, B) spreadsheets, C) “mail merge”, D) DTP.
- How the data needs processing after basic table extraction: A) is already data, B) needs “unpivotting”, C) needs fields picking out, D) needs tables picking out.
Which kinds of data PDF do you come across in your day to day work?
Try our easy web interface over at PDFTables.com!
Trackbacks/Pingbacks
[…] blog about the different sorts of table containing documents you often come across as PDFS: The four kinds of data PDF (“large tables”, “pivotted tables”, “transactions”, […]