PDF table extraction of pagenated table
Try our web interface and API over at PDFTables.com!
The Isle of Man aircraft registry (in PDF form) has long been a target of mine waiting for the appropriate PDF parsing technology. The scraper is here.
Setting aside the GetPDF() function, which deals with copying out each new pdf file as it is updated and backing it up into the database as a base64 encoded binary blob for quicker access, let’s have a look at the what the PDF itself looks like. I have snipped out the top left and top right hand corners of the document so you can see it more clearly.
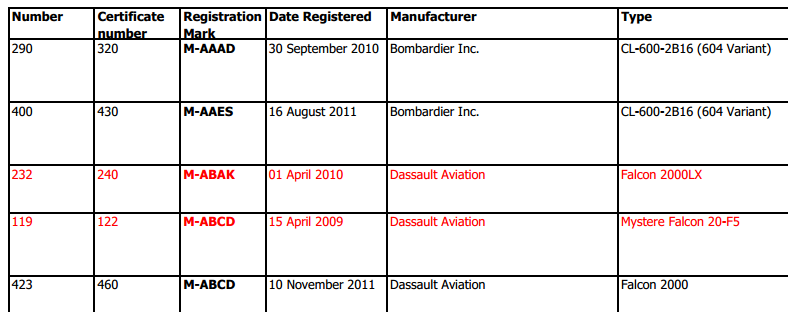
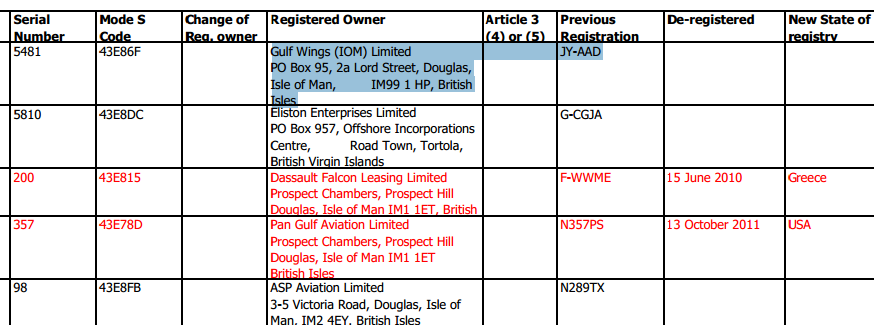
I have selected some of the text in one of the rows (in blue). Notice how the rectangle containing the first row of text crosses the vertical line between two cells of the table. This can make it rather tricky and requires you to analyze it at the character level.
It is essential to use a PDF extracting tool that gives you access to those dividing lines between the cells of the table. The only one I have found that does it is pdfminer, which is a pdf interpreter that is entirely written in Python.
Picking out the dividing lines
Extracting the dividing lines of the table is an unusual requirement (most applications simply want the raw text), so for the moment it looks like quite a hack. Fortunately that’s not a problem in ScraperWiki, and we can access the lower level components of the pdfminer functionality by importing these classes:
from pdfminer.pdfparser import PDFParser, PDFDocument, PDFNoOutlines, PDFSyntaxError from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LAParams, LTTextBox, LTTextLine, LTFigure, LTImage, LTTextLineHorizontal, LTTextBoxHorizontal, LTChar, LTRect, LTLine, LTAnon from binascii import b2a_hex from operator import itemgetter
Next you need some boilerplate code for running the PDFParser, which takes a file stream as input and breaks it down into separate page objects through a series of transformative steps. Internally the PDF file has an ascii part containing some special PDF commands which must be interpreted, followed by a binary blob which must be unzipped in order for its PostScript contents to be tokenized and then interpreted and rendered into the page space as if simulating a plotter.
cin = StringIO.StringIO()
cin.write(pdfbin)
cin.seek(0)
parser = PDFParser(cin)
doc = PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize("")
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
for n, page in enumerate(doc.get_pages()):
interpreter.process_page(page)
layout = device.get_result()
ParsePage(layout)
We’re now going to look into the ParsePage(layout) function where all the rendered components from the postscript are in layout containers, of which the top level is the page. We want to pull out just the horizontal and vertical lines, as well as the text. Sometimes what looks like a horizontal or vertical line is actually a thin rectangle. It all depends on the way the software that generated the PDF chooses to draw it.
xset, yset = set(), set()
tlines = [ ]
objstack = list(reversed(layout._objs))
while objstack:
b = objstack.pop()
if type(b) in [LTFigure, LTTextBox, LTTextLine, LTTextBoxHorizontal]:
objstack.extend(reversed(b._objs)) # put contents of aggregate object into stack
elif type(b) == LTTextLineHorizontal:
tlines.append(b)
elif type(b) == LTLine:
if b.x0 == b.x1:
xset.add(b.x0)
elif b.y0 == b.y1:
yset.add(b.y0)
else:
print "sloped line", b
elif type(b) == LTRect:
if b.x1 - b.x0 < 2.0:
xset.add(b.y0)
else:
yset.add(b.x0)
else:
assert False, "Unrecognized type: %s" % type(b)
To make it clearer, I am writing this code differently to how it appears in the scraper. As you build up this function you will discover how the generator of the PDF document chose to lay it out. You will adapt the code based on this information.
This is what we do: we interactively build up the code to efficiently target one particular type of document — where “type” means a document series all rendered the same way. If we can generalize this to some nearby types, then all the better. What we do not attempt to do at this stage is develop a general purpose PDF table extractor that works on everything.
As programmers who have confidence in our intelligence and abilities, this is always our instinct. But it doesn’t work in this domain. There are too many exceptional cases and layout horrors in these types of files that you will always be caught out. What began as your beautifully functional table extracting system will keep coming back with failures and more failed cases over and over again that you hack and fix until it looks like a Christmas turkey at the end of a meal. Even in this extremely simple table there are problems you cannot see. For example:

The phrase “Kingdom of Saudi Arabia” exists if you copy and paste it to text, but it has managed to be truncated by the edge of the table. Why hasn’t it been wordwrapped like ever other item of text in the table? I don’t know.
Slicing the text up between the lines
Moving on through the process, we now convert our diving lines into ordered arrays of x and y values. We’re taking clear advantage that the table occupies the entirety of each page — mainly to keep this tutorial simple because you want to know the techniques, not the specifics of this particular example. There are other tricks that work for more haphazard tables.
xlist = sorted(list(xset))
ylist = sorted(list(yset))
# initialize the output array of table text boxes
tboxes = [ [ [ ] for xl in xlist ] for yl in ylist ]
We also have the function which, given an x or y coordinate, returns the index of the dividing line we are between. (The boundary case of text going beyond the boundaries, like that “Kingdom of Saudi Arabia” example can be handled by discarding the last value in wlist.) This function uses a binary search.
def Wposition(wlist, w):
ilo, ihi = 0, len(wlist)
while ilo < ihi -1:
imid = (ilo + ihi) / 2
if w < wlist[imid]:
ihi = imid
else:
ilo = imid
return ilo
Normally we aren’t very interested in efficiency and would have simply done this with a for-loop, like so:
def Wposition(wlist, w):
for i, wl in enumerate(wlist):
if w < wl:
break
return i
However, we’re going to need to call this function a lot of times (at least once for each character in the PDF file), so we’re likely to run out of CPU time.
Here is the way I put the text from each text-line into the appropriate box, splitting up the characters when that text box happens to run across a vertical table boundary.
for lt in tlines:
y = (lt.y0+lt.y1)/2
iy = Wposition(ylist, y)
previx = None
for lct in lt:
if type(lct) == LTAnon:
continue # a junk element in LTTextLineHorizontal
x = (lct.x0+lct.x1)/2
ix = Wposition(xlist, x)
if previx != ix:
boxes[iy][ix].append([]) # begin new chain of characters
previx = ix
boxes[iy][ix][-1].append(lct.get_text())
Now the boxes contain lists of lists of characters. For example, the first two boxes in our two dimensional array of boxes is going to look like:
boxes[0][0] = [['N', 'u', 'm', 'b', 'e', 'r']] boxes[0][1] = [['C', 'e', 'r', 't', 'i', 'f', 'i', 'c', 'a', 't', 'e'], ['n', 'u', 'm', 'b', 'e', 'r']]
The next stage is to collapse these boxes down and extract the headers row from the table to check we have it right.
for iy in range(len(ylist)):
for ix in range(len(xlist)):
boxes[iy][ix] = [ "".join(s) for s in boxes[iy][ix] ]
headers = [ " ".join(lh.strip() for lh in h).strip() for h in boxes.pop() ]
assert headers == ['Number', 'Certificate number', 'Registration Mark', 'Date Registered', 'Manufacturer', 'Type', 'Serial Number', 'Mode S Code', 'Change of Reg. owner', 'Registered Owner', 'Article 3 (4) or (5)', 'Previous Registration', 'De-registered', 'New State of registry']
From here on we’re just interpreting a slightly dirty CSV file and there’s not much more to learn from it. Once a few more versions of the data come in I’ll be able to see what changes happen in this tables across the months and maybe find something out from that.
The exploration and visualization of the data is equally important as (if not more than) the scraping, although it can only be done afterwards. However, one often runs out of steam having reached this stage and doesn’t get round to finishing the whole job. There’s always the question: “So why the heck did I start scraping this data in the first place?” … in this case, I have forgotten the answer! I think it’s because I perceived that the emerging global aristocracy tends to jet between their tax-havens, such as the Isle of Man, in private planes that were sometimes registered there.
There are disappointingly fewer registrations than I thought there were – about 360, and only 15 (in the table grouped by manufacturer) are Learjets. I should have estimated the size of the table first.
At least we’re left with some pretty efficient table-parsing code. Do you have any more interesting PDF tables you’d like to run through it..?
Try our web interface and API over at PDFTables.com!
Thanks. This is really interesting. Only yesterday I was trying to extract something from:
http://www.justice.gov.uk/downloads/tribunals/lands/court-appeal-cases.pdf
So I could add value to this: https://scraperwiki.com/scrapers/lands-tribunal-decisions/ scraper. I’ve only just started poking around with pdfminer and I agree, its all completely hacky. I wrote something that pulled out lines in much the same way and it worked for *most* but not all the text on the first page I tried.
Probably more interesting to you would be this table:
http://www.justice.gov.uk/downloads/tribunals/information-rights/current-cases/information-rights-current-cases.pdf
which links up ICO case references with information tribunal case numbers. That link is not easily found elsewhere and could allow some sort of mashup between the ICO decisions and their IT appeals. I have managed to get the IT summaries all scraped, but going further would be nice.
If I have time I’ll work some more on this, but pdfminer is *not* well documented. I ended up looking at the source code to try to work out some of the objects.
Did you have a look at he work by McCallum on Table Extraction ? http://www.cs.umass.edu/~mccallum/papers/TableExtraction-irj06.pdf
this list comprehension just ends up empty for me:
tboxes = [ [ [ ] for xl in xlist ] for yl in ylist ]
are we missing something here?