NewsReader: the developers story
 ScraperWiki has been a partner in NewsReader, an EU Framework 7 research project, for the last couple of years. The aim of NewsReader is to give computers the power to “understand” the news; to extract from a myriad of news articles the underlying events which gave rise to those articles; the who, the where, the why and the what of those events. The project is comprised of academic researchers specialising in computational linguistics (VUA in Amsterdam, EHU in the Basque Country and FBK in Trento), Lexis Nexis – a major news aggregator, and a couple of small technology companies: ourselves at ScraperWiki and SynerScope – a Dutch startup specialising in the visualisation of complex networks.
ScraperWiki has been a partner in NewsReader, an EU Framework 7 research project, for the last couple of years. The aim of NewsReader is to give computers the power to “understand” the news; to extract from a myriad of news articles the underlying events which gave rise to those articles; the who, the where, the why and the what of those events. The project is comprised of academic researchers specialising in computational linguistics (VUA in Amsterdam, EHU in the Basque Country and FBK in Trento), Lexis Nexis – a major news aggregator, and a couple of small technology companies: ourselves at ScraperWiki and SynerScope – a Dutch startup specialising in the visualisation of complex networks.
Our role at ScraperWiki is in providing mechanisms to enable developers to exploit the NewsReader technology, and to feed news into the system. As part of this work we have developed a simple REST API which gives access to the KnowledgeStore, the system which underpins NewsReader. The native query language of the KnowledgeStore is SPARQL – the query language of the semantic web. The Simple API provides a set of predefined queries which are easier for end users to work with than raw SPARQL, and help us as service managers by providing a predictable set of optimised queries. If you want to know more technical detail then we’ve written a paper about it (here).
The Simple API has seen live action at a Hack Day on World Cup news which we held in London in the summer. Attendees were able to develop a range of applications which probed violence, money and corruption in the realm of the World Cup. I blogged about our previous Hack Day here and here. The Simple API, and the Hack Day helped us shake out some bugs and add features which will make it even better next time.
“Next time” is another Hack Day to be held in the Amsterdam on 21st January 2015, and London on the 30th January 2015. This time we have processed 6,000,000 articles relating to the car industry over the period 2005-2014. The motor industry is a trillion dollar a year business, so we can anticipate finding lots of valuable information in this horde.
From our previous experience the three things that NewsReader excels at are:
- Finding networks of interactions, identifying important players. For the World Cup Hack Day we at ScraperWiki were handicapped slightly by having no interest in football! But the NewsReader technology enabled us to quickly identify that “Sepp Blatter”, “Jack Warner” and “Mohammed bin Hammam” were important in world football. This is illustrated in this slightly cryptic visualisation made using Gephi:
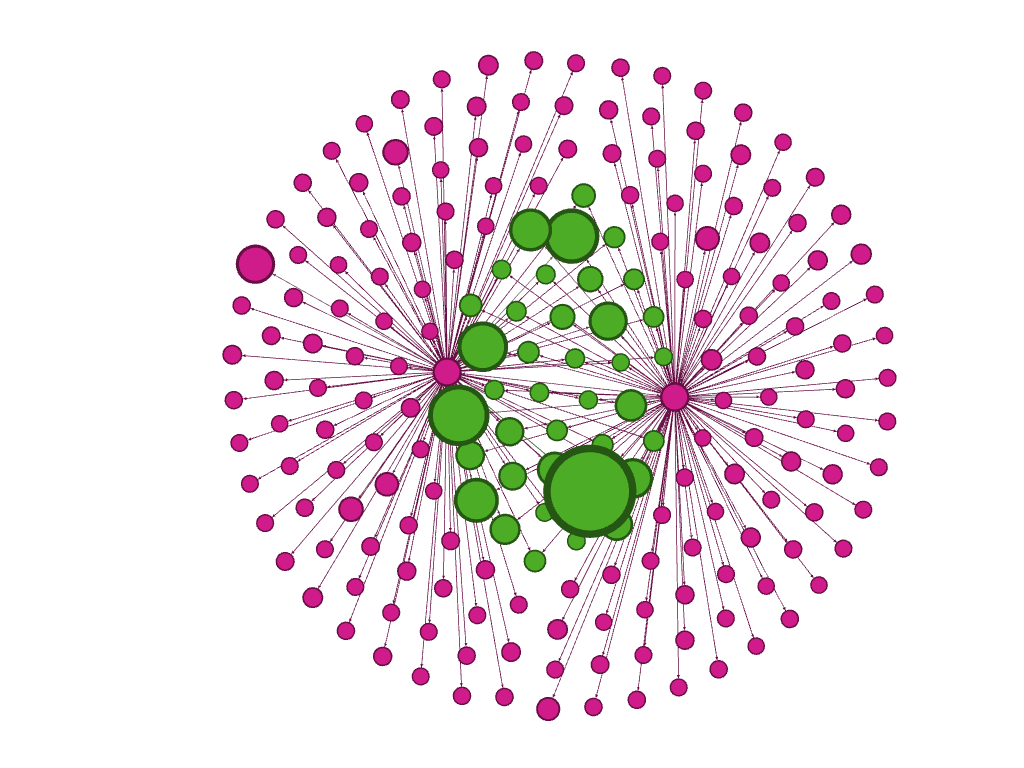
- Finding events of a particular type. the NewsReader technology carries out semantic role labeling: taking sentences and identifying what type of event is described in that sentence and what roles the participants took. This information is then aggregated and exposed using semantic web technology. In the World Cup Hack Day participants used this functionality to identify events involving violence, bribery, gambling, and other financial transactions;
- Establishing timelines. In the World Cup data we could track the events involving “Mohammed bin Hammam” through time and the type of events he was involved in. This enabled us to quickly navigate to pertinent news articles.
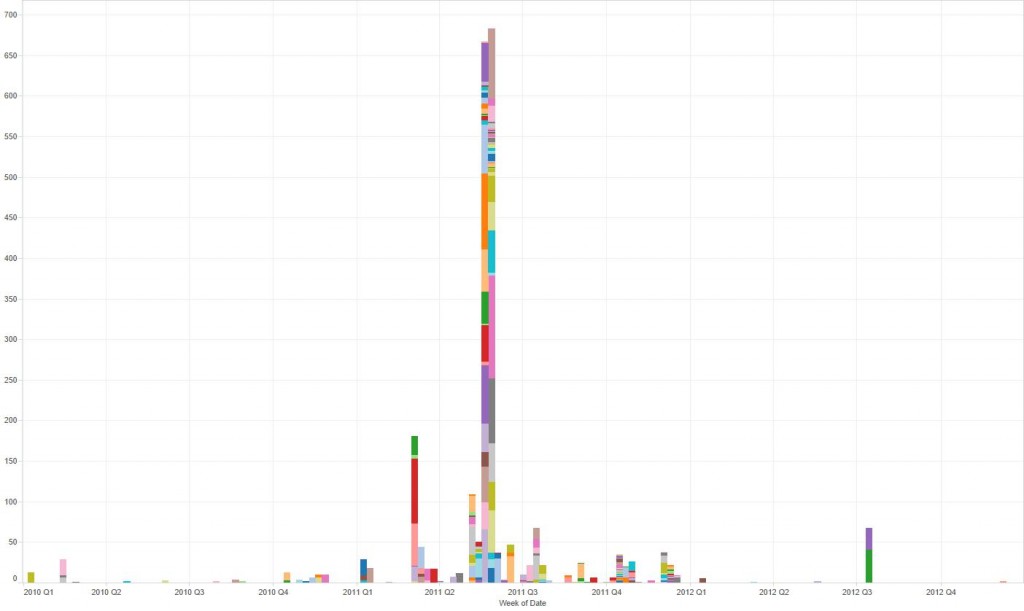
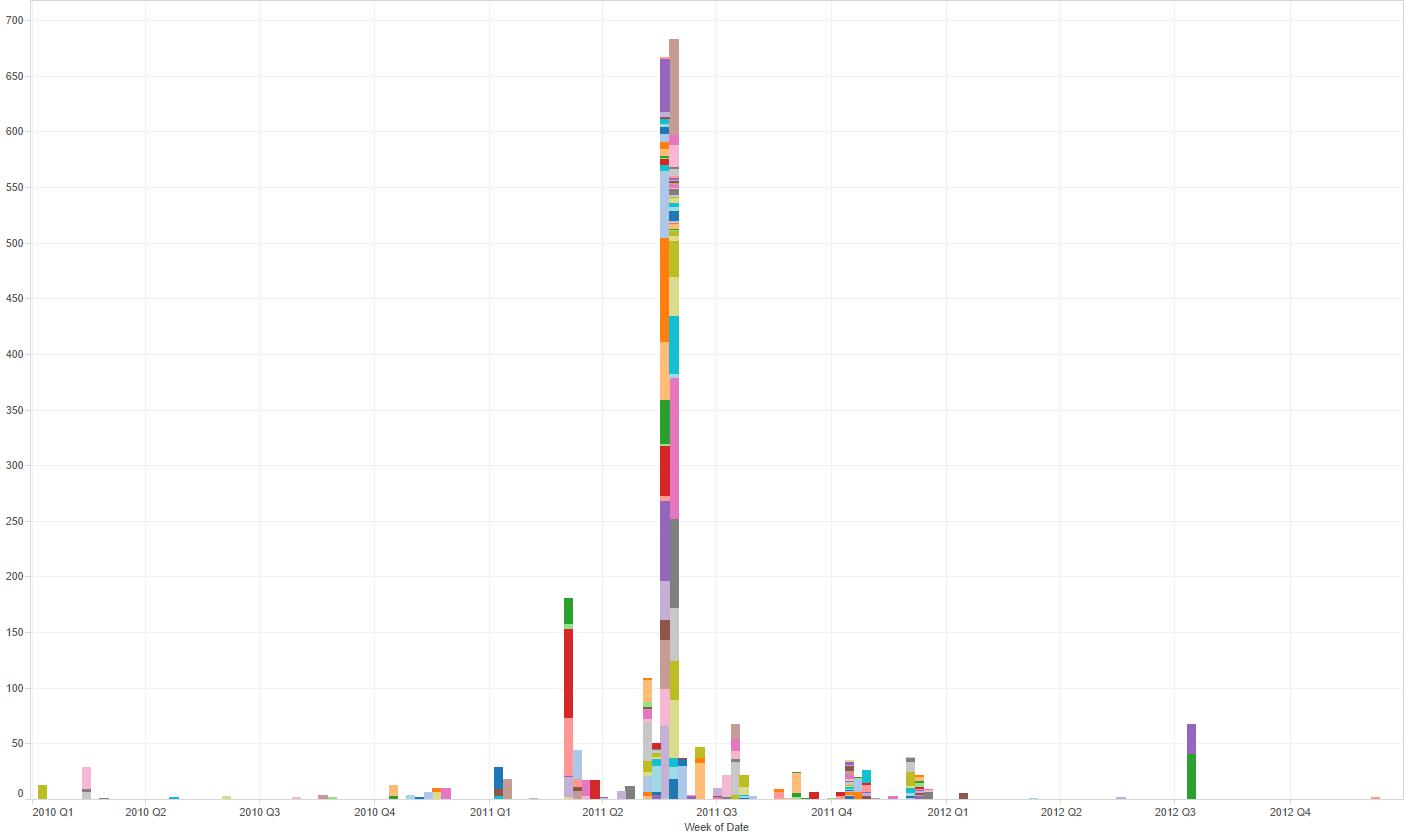
You can see fragments of code used to extract these data using the Simple API in these GitHub Gists (here and here), and dynamic visualisations illustrating these three features here and here.
The Simple API is up and running already, you can find it (here). It is self-documenting, simply visit the root URL and you’ll see query examples with optional and compulsory parameters. Be aware though: the Simple API is under active development, and the underlying data in the KnowledgeStore is being optimised for the Hack Days so it may not be available when you visit.
If you want to join our automotive Hack Day then you can sign up for the Amsterdam event (here) and the London event (here).
Trackbacks/Pingbacks
[…] NewsReader: the developers story […]