ScraperWiki and Enemy Images
This is a guest blog post by Elizaveta Gaufman, a researcher and lecturer at the University of Tübingen.
The theme of my PhD dissertation is enemy images in contemporary Russia.
However, I am not only interested in the governmental rhetoric which is relatively easy to analyse, but also in the way enemy images are circulating on the popular level. As I don’t have an IT background I was constantly looking for easy-to-use tools that would help me analyse the data from social networks, which for me represent a sort of a petri dish of social experimentation. Before I came across ScraperWiki I had to use a bunch of separate tools to analyse data: I had to scrape the data with one tool, then visualise it with another and ultimately create word clouds with the most frequently used terms with a third tool. A separate problem was scraping visuals, which in my previous methodology was not possible.
In my dissertation I conceptualize of enemy images as ‘an ensemble of negative conceptions that describes a particular group as threatening to the referent object’. As an enemy image is not so easy to operationalize, or to create a query for, I filtered a list of threats through opinion poll data and another tool that helped me establish which threats are debated in Russian mass media (both print and online). Then was ScraperWiki’s turn.
ScraperWiki allows its user to analyse the information on the cloud, including the number of re-tweets, frequency analysis of the tweet texts, language, and a number of other parameters, including visuals which is extremely useful for my research. Another advantage is that I did not need to download any social network analysis programs that run on Windows anyway, while I have a Mac. In order to analyse Twitter data, firstly, I input the identified threats in the separate datasets that extract tweets from Cyrillic segment of Twitter, because the threats are in Cyrillic as well (in case of Pussy Riot, e. g., I input in Cyrillic transliteration of it as ‘Пусси’).
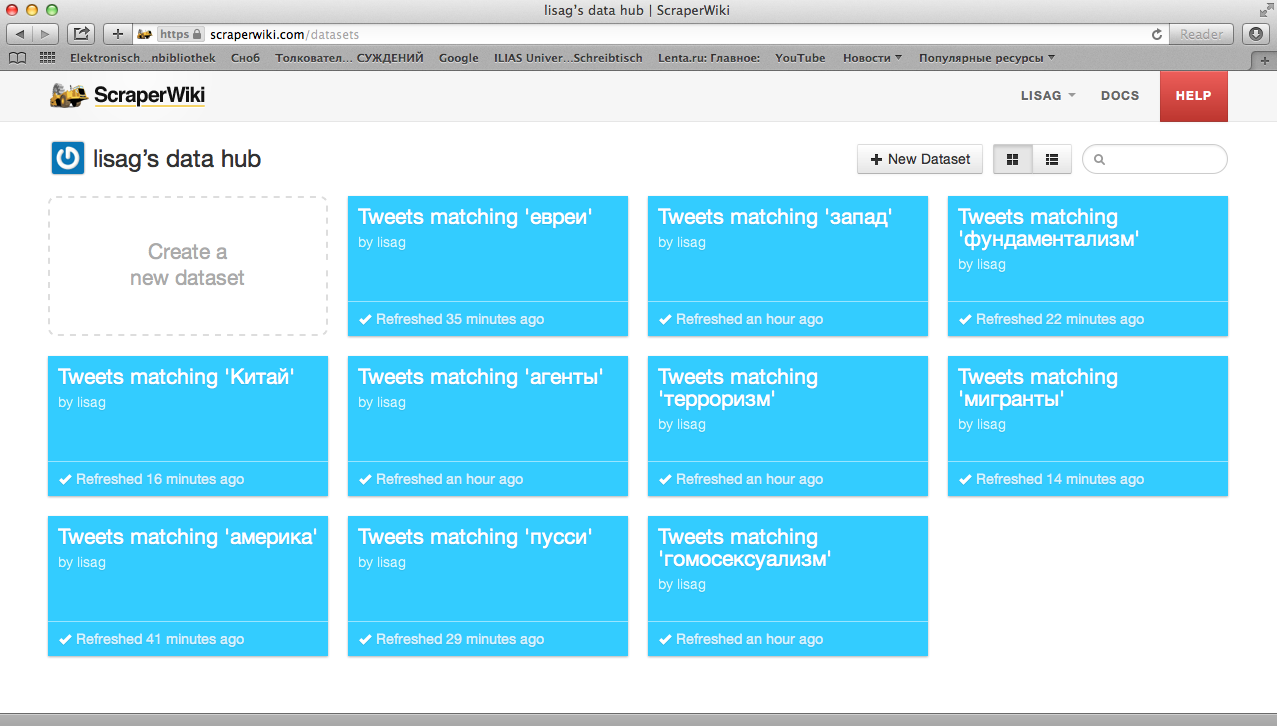
The maximum allowed number of datasets on the cheaper plan is 10, so I included 8 threats that scored on both parameters from my previous filtering (the West, fundamentalism, China, terrorism, inter-ethnic conflict, the US, Pussy Riot and homosexuality) and subsequently tested the remaining threats (Georgia, Estonia, foreign agents, Western investment, and Jews) to check which ones will yield more Tweets in order to be included in the dataset. Surprisingly enough, the two extra datasets ended up being ‘foreign agents’ and ‘Jews’ that completed my data hub. In order to illustrate the features of Scraperwiki, I show two screenshots below that explain the data visualization.
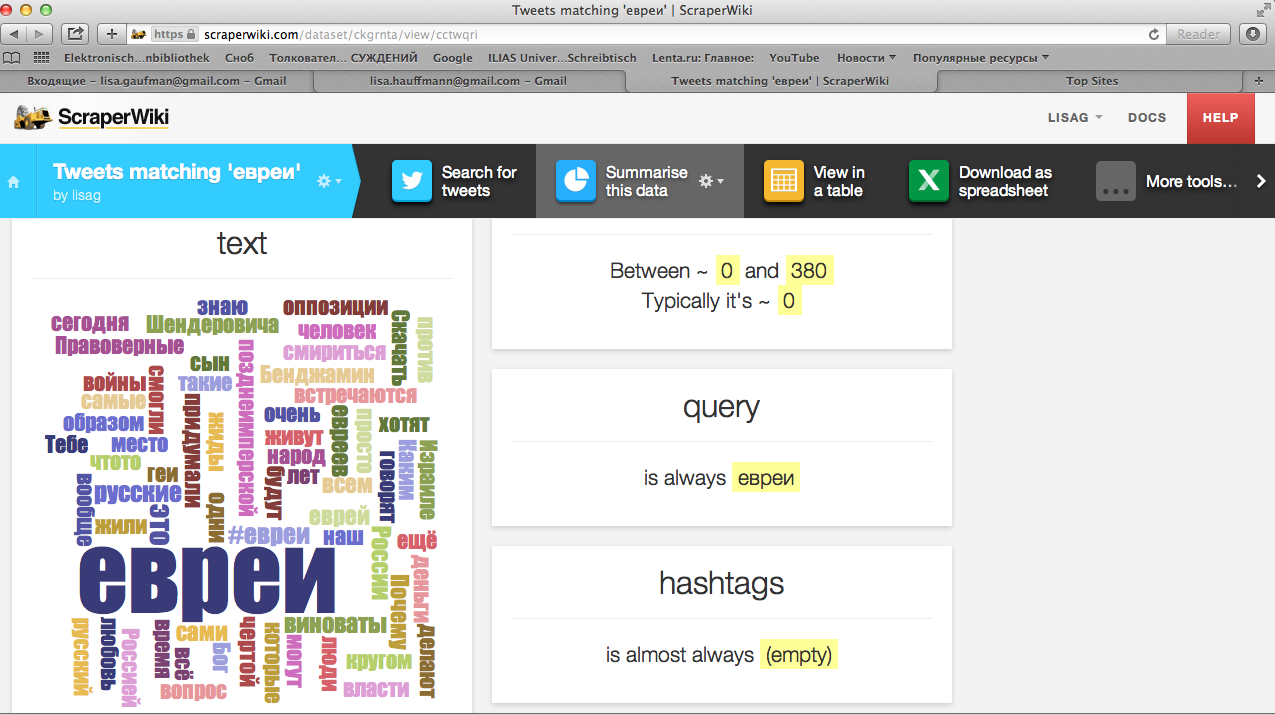
The most important data for my dissertation on Screenshot 2 is the word frequency analysis that shows what kind of words were used the most in the tweets in this case from the query ‘yevrei’ (Jews). Scraperwiki also offers an option to view the data in the table, so it is also possible to view the ‘raw’ data and close-read the relevant tweets that in this dataset include the words ‘vinovaty’ (guilty), ‘den’gi’ (money), ‘zhidy’ (kikes) etc, but even without the close-reading some of the frequently used words reveal ‘negative conceptions about a group of people’ that represent the cornerstone of an enemy image.

Second most important data for my dissertation is contained in the section ‘media’ where the collection of tweeted pictures is summarized. The visuals from this collection are sorted from the most to least re-tweeted and I can then analyse them according to my visual analysis methodology.
Even though ScraperWiki provides a lot of solutions to my data collection and analysis problems, my analysis is easier to carry out because of the language: Cyrillic provides a sort of a cut-off principle for the tweets that would not be possible with the English language (unless ScraperWiki adds a feature that would allow for geographic filtering of the tweets). But in general it is a great solution for social scientists like me who do not have a lot of funding or substantial IT knowledge, but still want to perform solid research involving big data.