Civil Service People Survey – Faster, Better, Cheaper

Civil Service Reporting Platform
The Civil Service is one of the UK’s largest employers. Every year it asks every civil servant what it thinks of its employer: UK plc.
For Sir Jeremy Heywood the survey matters. In his blog post “Why is the People Survey Important?” he says
“The survey is one of the few ways we can objectively compare, on the basis of concrete data, how things are going across departments and agencies. …. there are common challenges such as leadership, improving skills, pay and reward, work-life balance, performance management, bullying and so on where we can all share learning.”
The data is collected by a professional survey company called ORC International. The results of the survey have always been available to survey managers and senior civil servants as PDF reports. There is access to advanced functionality within ORC’s system to allow survey managers more granular analysis.
So here’s the issue. The Cabinet Office wants to give access to all civil servants and in a fast and reliable way. It wants to give more choice and speed in how the data is sliced and diced – in real time. Like all government departments it is also under pressure to cut costs.
ScraperWiki built a new Civil Service People Survey Reporting Platform and it’s been challenging. It’s a moderately large data set. There’s close to half a million civil servants – over 250,000 answered the last survey which contains 100 questions. There are 9000 units across government. This means 30,000,000 rows of data per annum and we’ve ingested 5 years of data.
The real challenges were around:
- Data Privacy
- Real Time Querying
- Design
Data privacy
The civil servants are answering questions on their attitudes to their work, their managers, the organisations they worked in along with questions on who they are: gender, ethnicity, sexual orientation – demographic information. Their responses are strictly confidential and one of the core challenges of the work is maintaining this confidentiality in a tool available over the internet, with a wide range of data filtering and slicing functionality.
A naïve implementation would reveal an individual’s responses either directly (i.e. if they are the only person in a particular demographic group in a particular unit), or indirectly, by taking the data from two different views and taking a difference to reveal the individual. ScraperWiki researched and implemented a complex set of suppression algorithms to allow publishing of the data without breaking confidentiality.
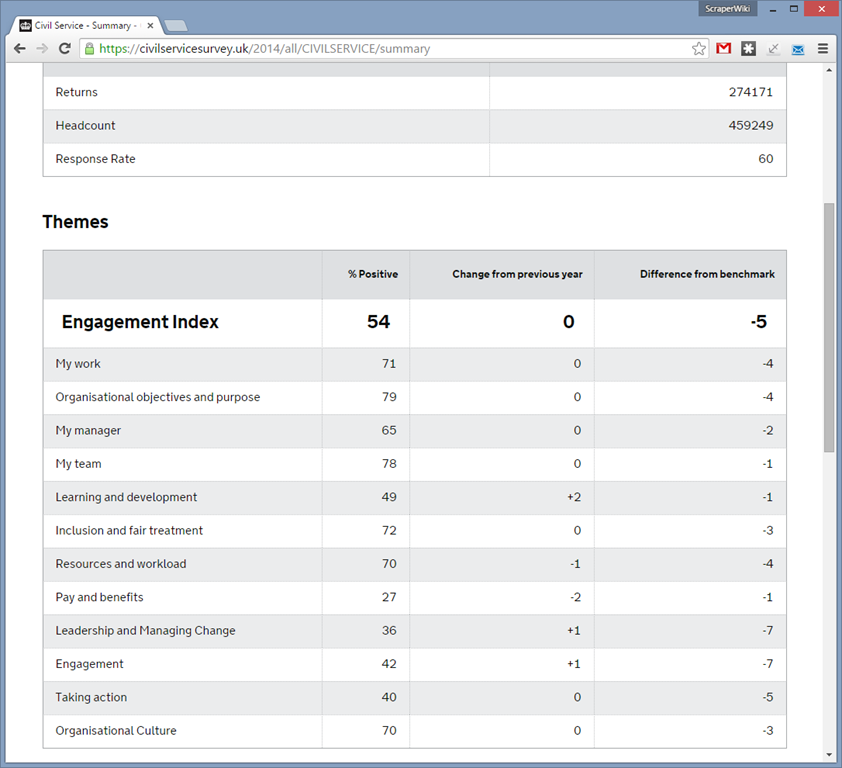
Real-time queries
Each year the survey generates 30,000,000 data points, one for each answer given by each person. This is multiplied by five years of historical data. To enable a wide range of queries our system processes this data for every user request, rather than rely on pre-computed tables which would limit the range of available queries.
Aside from the moderate size, the People Survey data is rich because of the complexity of the Civil Service organisational structure. There are over 9,000 units in the hierarchy which is in some places up to 9 links deep. The hierarchy is used to determine how the data are aggregated for display.
Standard design
 An earlier design decision was to use the design guidelines and libraries developed by the Government Digital Service for the GOV.UK website. This means the Reporting Platform has the look and feel of GOV.UK., and we hope follows their excellent usability guidelines.
An earlier design decision was to use the design guidelines and libraries developed by the Government Digital Service for the GOV.UK website. This means the Reporting Platform has the look and feel of GOV.UK., and we hope follows their excellent usability guidelines.
Going forward
The People Survey digital reporting platform alpha was put into the hands of survey managers at the end of last year. We hope to launch the tool to the whole civil service after the 2015 survey which will be held in October. If you aren’t a survey manager, you can get a flavour of the People Survey Digital Reporting Platform in the screenshots in this post.
Do you have statistical data you’d like to publish more widely, and query in lightning fast time? If so, get in touch.